
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 Redis的高可用机制有持久化、复制、哨兵和集群。其主要的作用和解决的问题分别是:
本文这里将介绍Redis的哨兵机制。
Redis的主从模式重点在于解决整体的承压能力,利用从节点分担读取操作的压力。但是其在 容错恢复 等可靠性层面欠缺明显, 不具备 自动的故障转移与恢复能力:
当然,master节点故障后,也可以手动将其中一个从节点切换为新的master节点来恢复故障。而原先的master节点恢复后,需要手动将其降级为slave节点,对外提供只读服务。
实际使用的时候,手动故障恢复的时效无法得到保证,为了支持自动的故障转移与恢复能力,Redis在主从模式的基础上进行优化增强,提供了哨兵(Sentinel)架构模式。
那么就需要有一个机制,能够监测主节点是否存活,如果发现主节点挂了,就选举一个从节点切换为主节点,并且把新主节点的相关信息通知给从节点和客户端。
那么就有以下三个问题需要解决:
Redis的哨兵模式,就是在主从模式的基础上,额外部署若干独立的哨兵进程,通过哨兵进程去监视者Redis主从节点的状态,一旦发现主节点宕机,则哨兵可以重新从剩余slave节点中推选一个新的节点并将其升级为master节点,以此保证整个系统功能可以正常使用。
哨兵负责三个任务:监控,选主(选择主库)和通知。
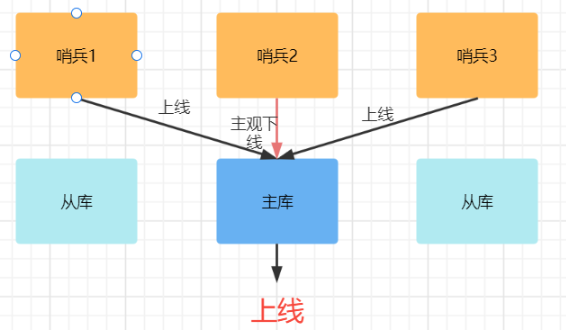
哨兵进程会使用PING命令检测主和从库的连接情况,用来判断实例状态;
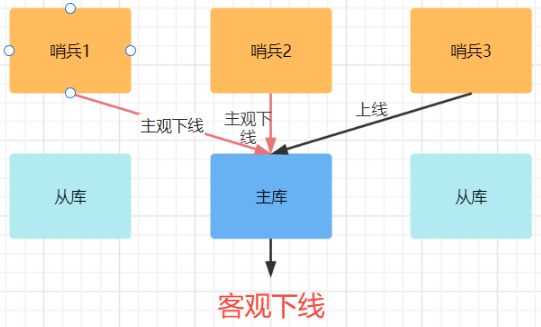
如果哨兵发现主库或者从库对PING命令响应超时,那么哨兵就会把它标记为"主观下线"。
确认主库下线了,主库才能被标记为客观下线。需要注意的是客观下线是主节点才有的概念;如果从节点和哨兵节点发生故障,被哨兵主观下线后,不会再有后续的客观下线和故障转移操作。
什么是误判?
主库实际没有下线,但是哨兵以为它下线了。误判产生原因:比如集群网络压力较大,出现网络拥塞,或者主库本身压力较大,导致主节点没有在规定时间内响应哨兵的 PING 命令。
因此,这里有两个问题:
哨兵集群:哨兵以多实例组成的集群模式进行部署(最少需要三台机器来部署哨兵集群)。通过多个哨兵节点一起判断,就可以就可以避免单个哨兵因为自身网络状况不好,而误判主节点下线的情况。同时,多个哨兵网络同时不稳定的概率较小,让它们一起决策让误判率降低。
当一个哨兵判断主库为主观下线后就会向其它哨兵发起协商,其它哨兵就会根据自身与主库的网络状况,做出赞成或拒绝投票的响应。
而只有大多数哨兵实例判断主库都已经"主观下线",主库才会被标记"客观下线",——— 即少数服从多数机制
当这个哨兵的赞同票数达到哨兵配置文件中的
quorum
配置项设定的值后,这时主节点就会被该哨兵标记为客观下线。
"客观下线":N个哨兵实例,最好要有N/2+1个实例判断主库为"主观下线",才能判断为"客观下线"。
为了减少误判概率,所以哨兵是以哨兵集群的方式存在的,以少数服从多数的机制来判断主库是否真的挂了。
那么既然是集群,由哨兵集群中的哪个节点进行主从故障转移呢?
所以这时候,还需要在哨兵集群中选出一个 leader,让 leader 来执行主从切换。
leader是从候选者中产生的,哪个哨兵节点判断主节点为 客观下线 ,这个哨兵节点就是leader的候选者。
假设有三个哨兵。当哨兵 B 先判断到主节点主观下线后,就会给其他实例发送 is-master-down-by-addr 命令。接着,其他哨兵会根据自己和主节点的网络连接情况,做出赞成投票或者拒绝投票的响应。当哨兵 B 收到赞成票数达到哨兵配置文件中的 quorum 配置项设定的值后,就会将主节点标记为 客观下线,此时的哨兵 B 就是一个Leader 的候选者。
判断主库客观下线后只是Leader 的候选者,还不是Leader
由于quorum 配置问题,有可能判断主库客观下线的哨兵有多个。比如有3个哨兵,quorum为2,AB都认为主库主观下线,C认为主库还在线,因此此时哨兵A收到主观下线的值为2,另一个哨兵B收到的主观下线值也为2,由于这两个值都大于等于quorum,因此哨兵A和哨兵B都会将主库标记为客观下线。但不能让哨兵A和哨兵B同时执行主从切换。因此需要从哨兵A和哨兵B中选出一个Leader来执行主从切换
此时Leader候选者会向其他哨兵发送命令,表明希望成为 Leader 来执行主从切换,并让所有其他哨兵对它进行投票。
每个哨兵只有一次投票机会,如果用完后就不能参与投票了,可以投给自己或投给别人,但是只有Leader候选者才能把票投给自己。
那么只要 Leader候选者 同时满足以下两个条件,就可以成为Leader:
也就是说,选举的票数大于等于num(sentinel)/2+1时,Leader候选者 将成为 Leader,如果没有超过继续选举
所以,quorum 的值建议设置为哨兵个数的二分之一加1,例如 3 个哨兵就设置 2,5 个哨兵设置为 3,而且哨兵节点的数量应该是奇数
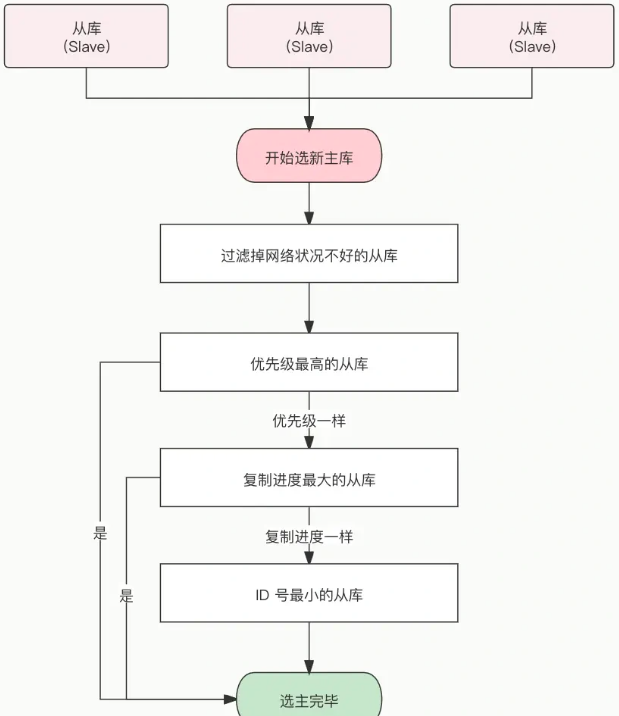
哨兵判断主节点客观下线后,哨兵就要开始在从节点中选出一个从节点来做新主节点
这里大家是不是和我一样有个疑惑?如果三个哨兵同时判断为主观下线,那么就有可能同时判断为客观下线,那么就都是leader候选者了,那么在投票时也都投给了自己,那么leader不就永远选不出来了吗?
首先,哨兵对主从库进行的在线状态检查的操作,是属于一种时间事件,用一个定时器来完成,一般来说每100ms执行一次这些事件。实际上每个哨兵的定时器执行周期都会加上一个小小的随机时间偏移,目的是让每个哨兵执行上述操作的时间能稍微错开些,也是为了避免它们都同时判定主库主观下线。
其次,实际上不同哨兵的网络情况、系统的压力一般不完全一样,接收到主观下线协商消息的时间也就可能不同,所以,它们同时做出主库客观下线判定的概率较小,一般也就有个先后关系。
最后,即使出现了都投给自己一票的情况,导致无法选出Leader,哨兵会停一段时间(一般是故障转移超时时间failover_timeout的2倍),然后再可以进行下一轮投票。
选定新主库是 筛选 ➕ 打分的过程
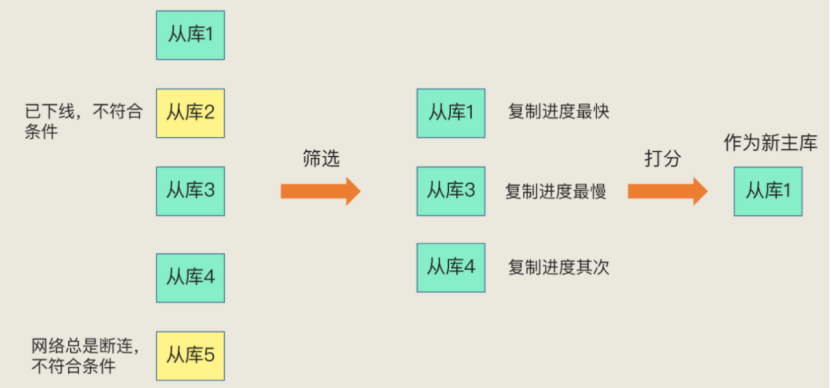
首先要把网络状态不好的从节点给过滤掉。首先把已经下线的从节点过滤掉,然后把以往网络连接状态不好的从节点也给过滤掉。
判断方式:
使用配置项down-after-milliseconds*10。down-after-milliseconds是主从节点断连的最大连接超时时间。如果在 down-after-milliseconds 毫秒内,主从节点都没有通过网络联系上,我们就可以认为主从节点断连了。如果这个断连次数超过10次,说明从库网络状态不好,不适合作为新主库。
优先级、复制进度、ID 号
如何判断从库和旧主库间的同步进度?
从库的slave_repl_offset最接近旧主库的master_repl_offset,那么它的得分最高,可以作为新主库。
在选举出从节点为新主节点后后,哨兵 leader 向被选中的从节点发送 SLAVEOF no one 命令,让这个从节点解除从节点的身份,将其变为新主节点。
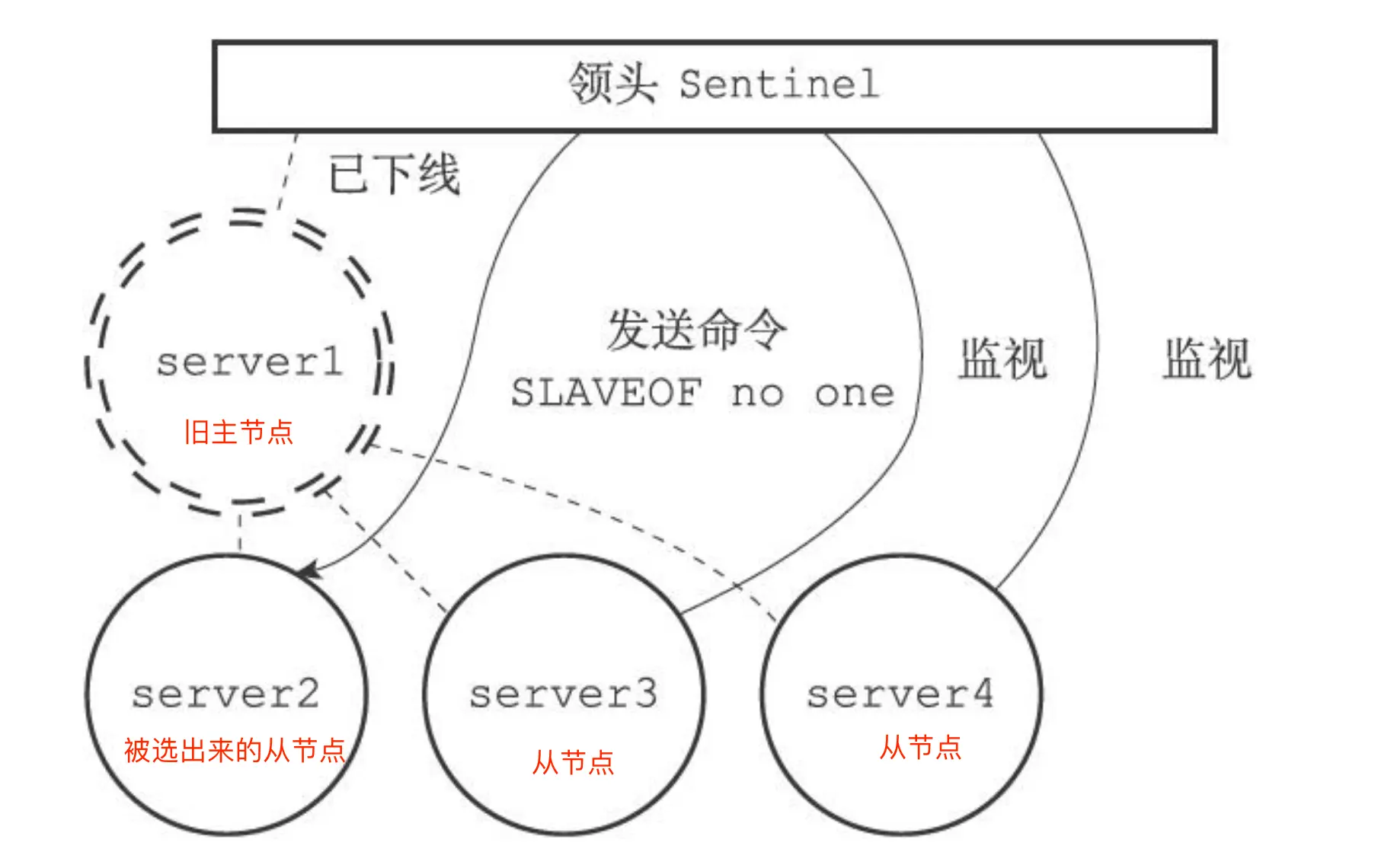
哨兵 leader 下一步要做的就是,让已下线主节点属下的所有从节点指向新主节点,这一动作可以通过向从节点发送 SLAVEOF 命令来实现。
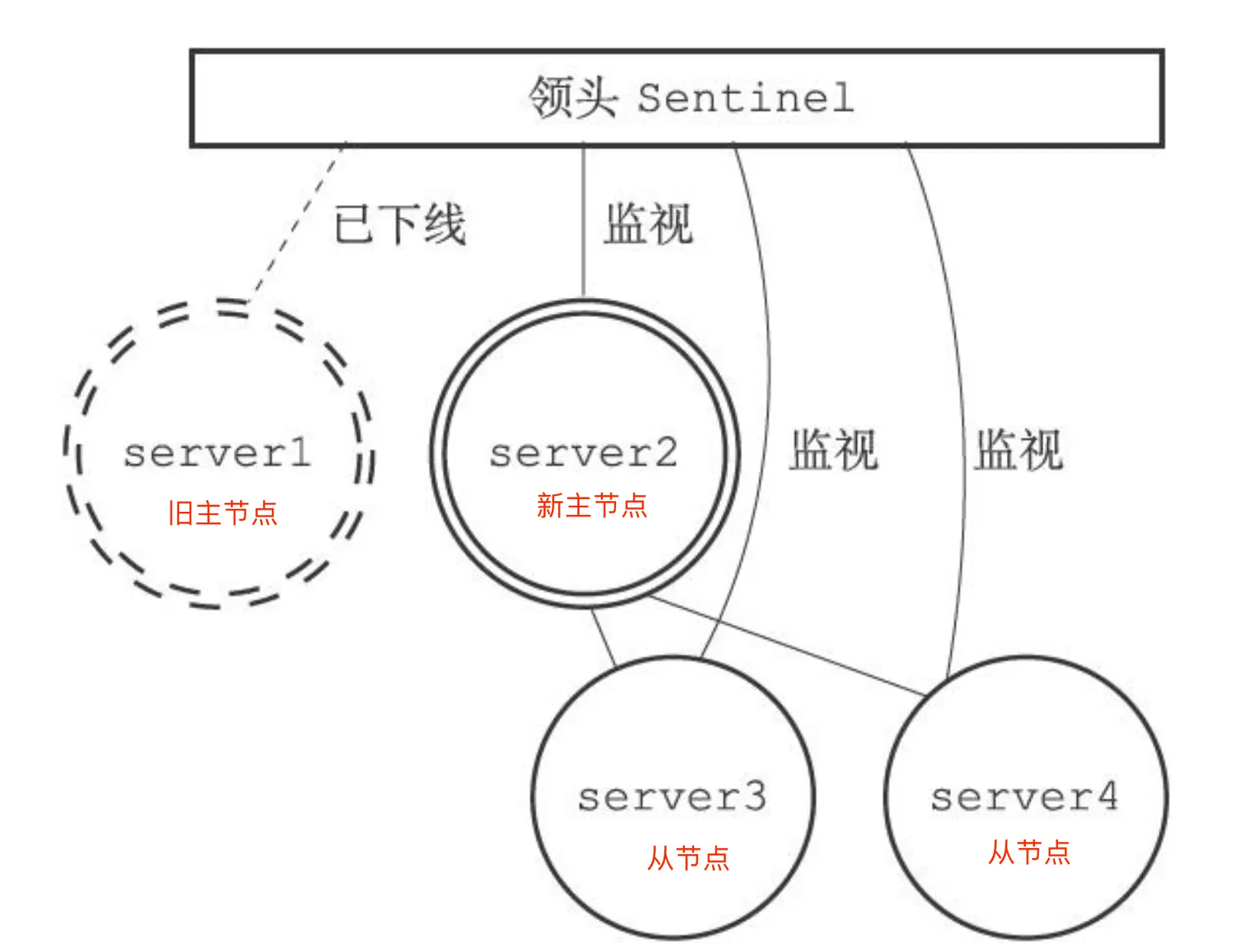
这主要通过 Redis 的发布者/订阅者机制来实现的。每个哨兵节点提供发布者/订阅者机制,客户端可以从哨兵订阅消息。
哨兵提供的消息订阅频道有很多,不同频道包含了主从节点切换过程中的不同关键事件,几个常见的事件如下:
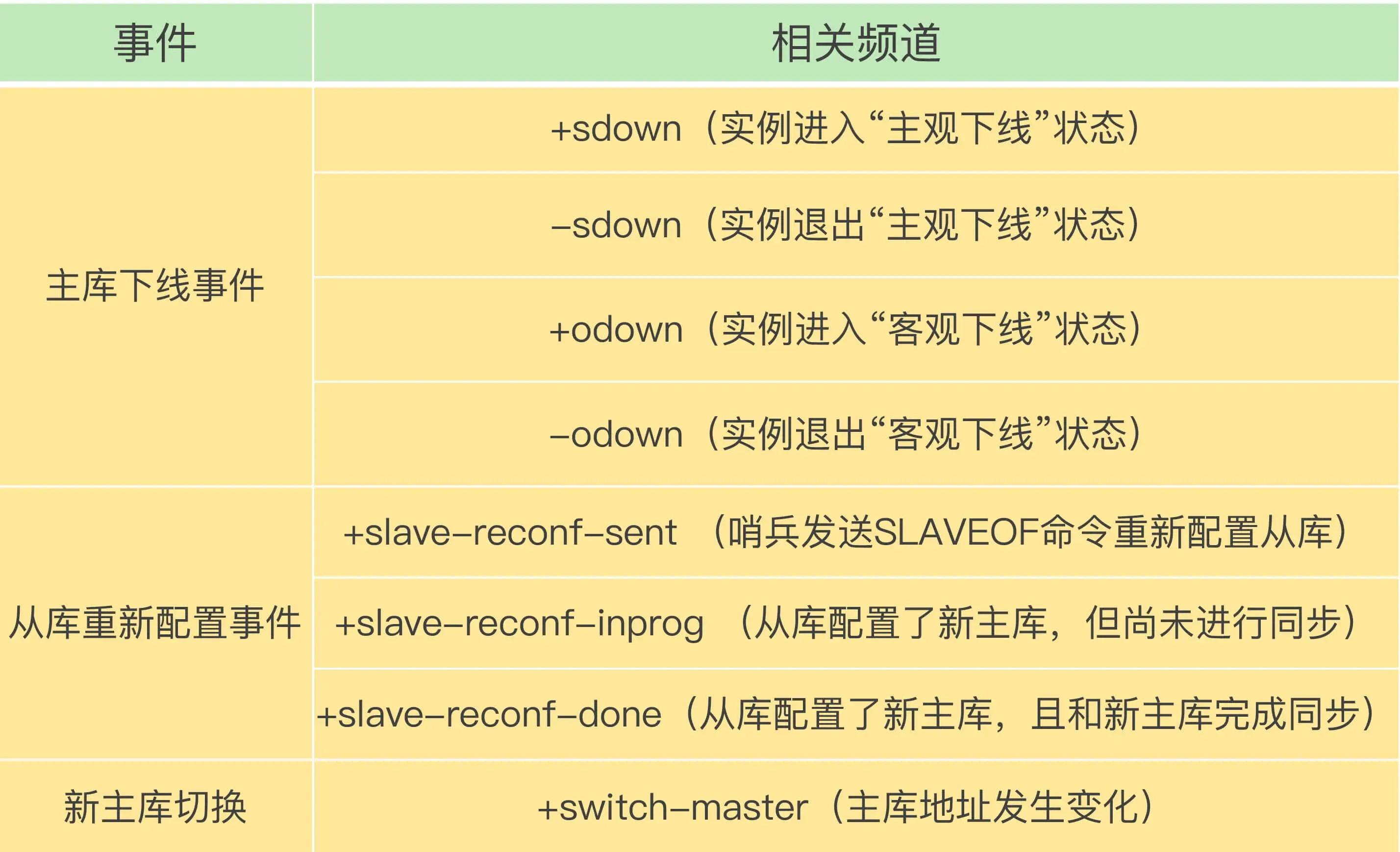
客户端和哨兵建立连接后,客户端会订阅哨兵提供的频道。主从切换完成后, 哨兵就会向 +switch-master 频道发布新主节点的 IP 地址和端口的消息,这个时候客户端就可以收到这条信息,然后用这里面的新主节点的 IP 地址和端口进行通信了 。
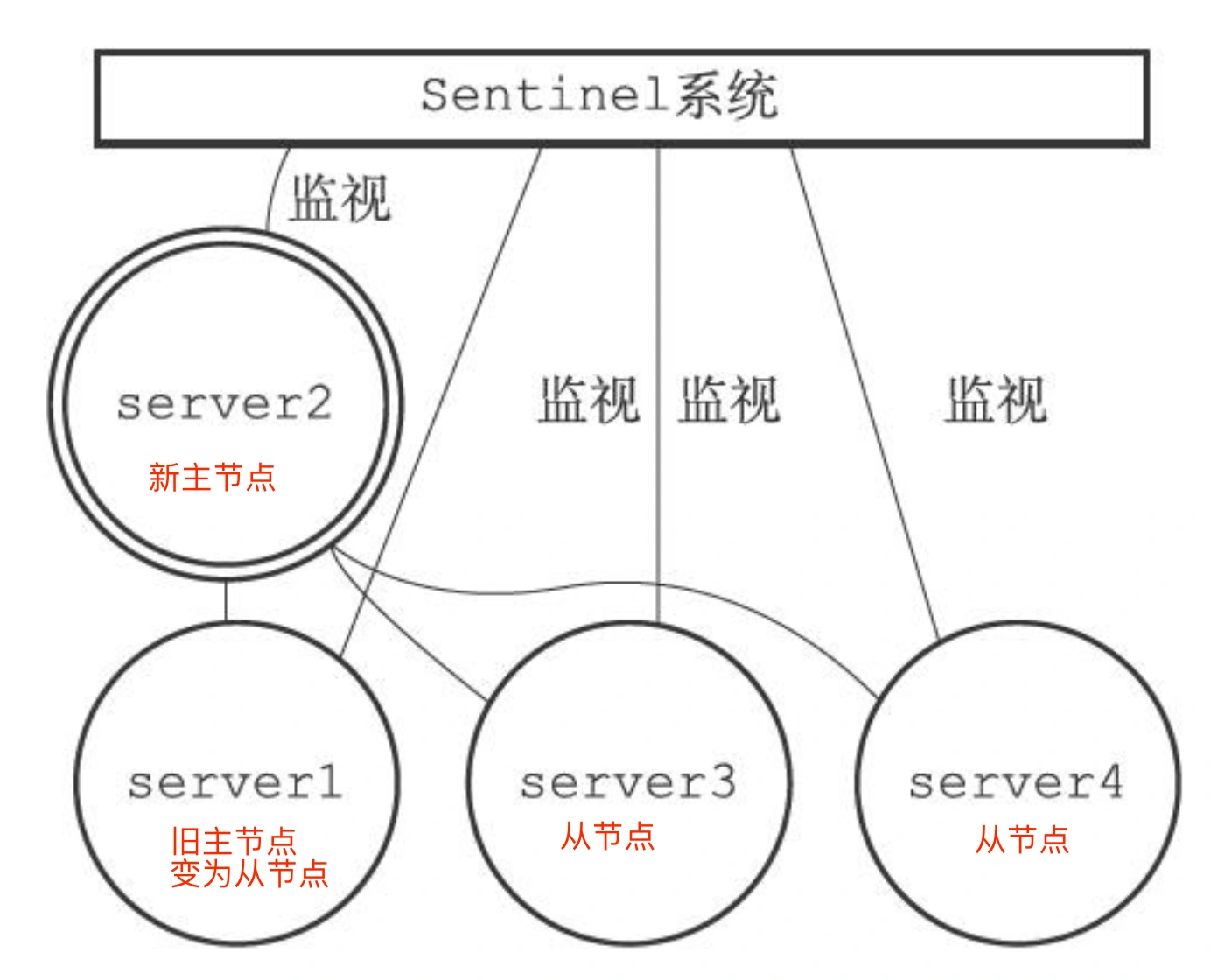
继续监视旧主节点,当旧主节点重新上线时,哨兵集群就会向它发送 SLAVEOF 命令,让它成为新主节点的从节点
由于redis是单线程运行的,如果有命令超过3秒,哨兵心跳检查就会失败,最终导致频繁切换主从和脑裂情况
本文首先介绍了哨兵的作用:监控、选主、通知;主要是实现主从节点故障转移。哨兵集群会监测主节点是否存活,如果发现主节点挂了,它就会选举一个从节点切换为主节点,并且把新主节点的相关信息通知给从节点和客户端。
哨兵机制具体步骤如下:
在主从复制的基础上,哨兵引入了主节点的自动故障转移,进一步提高了Redis的高可用性;但是哨兵的缺陷同样很明显:哨兵无法对从节点进行自动故障转移,在读写分离场景下,从节点故障会导致读服务不可用,这就需要对从节点做额外的监控、切换操作。 此外,哨兵仍然没有解决写操作无法负载均衡、存储能力受到单机限制的问题;这些问题的解决需要使用集群,有时间再学习集群方面的知识~
Java面试题专栏 已上线,欢迎访问。
那么可以私信我,我会尽我所能帮助你。
热门资讯







