
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 我们是 袋鼠云数栈 UED 团队 ,致力于打造优秀的一站式数据中台产品。我们始终保持工匠精神,探索前端道路,为社区积累并传播经验价值。
本文作者:文长
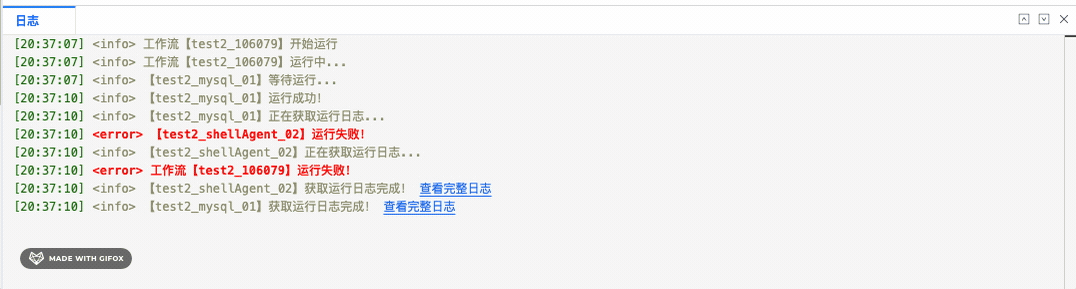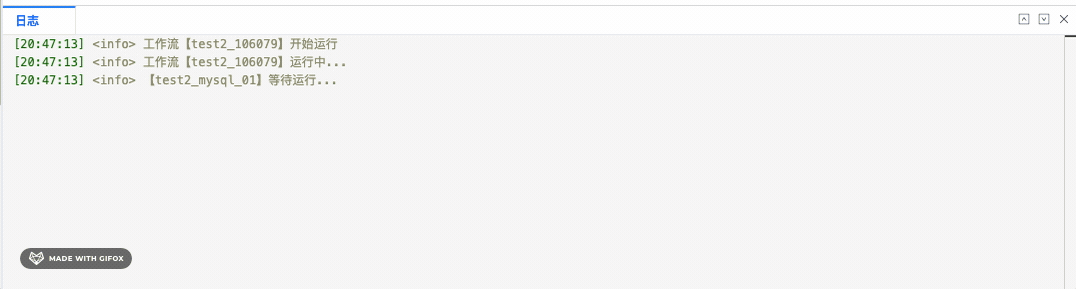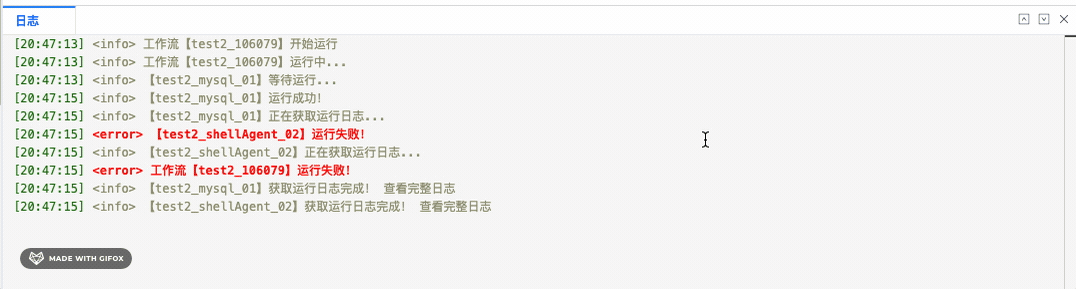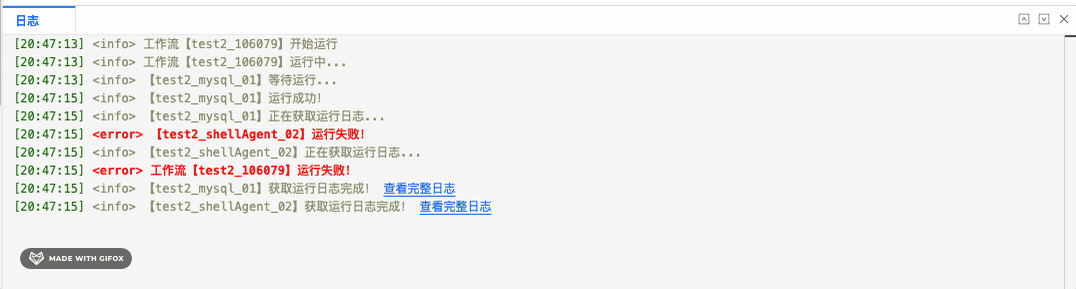
在 Web IDE 中,控制台中展示日志是至关重要的功能。Monaco Editor 作为一个强大的代码编辑器,提供了丰富的功能和灵活的 API ,支持为内容进行“装饰”,非常适合用来构建日志展示器。如下图:
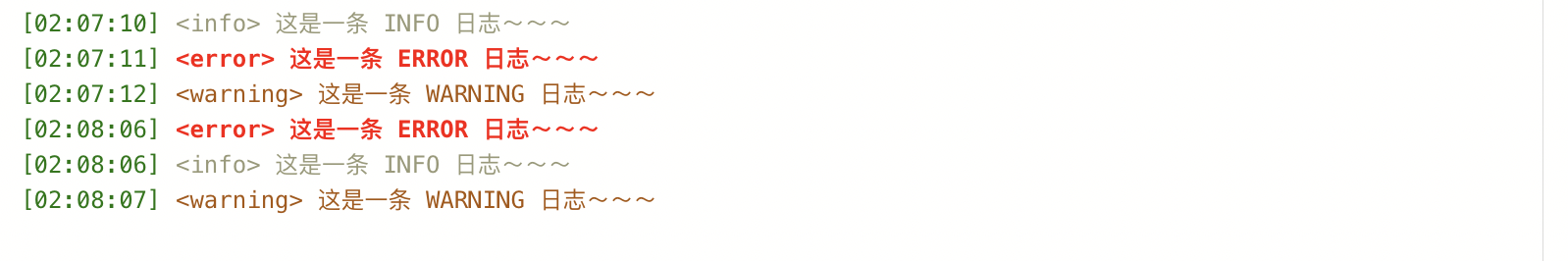
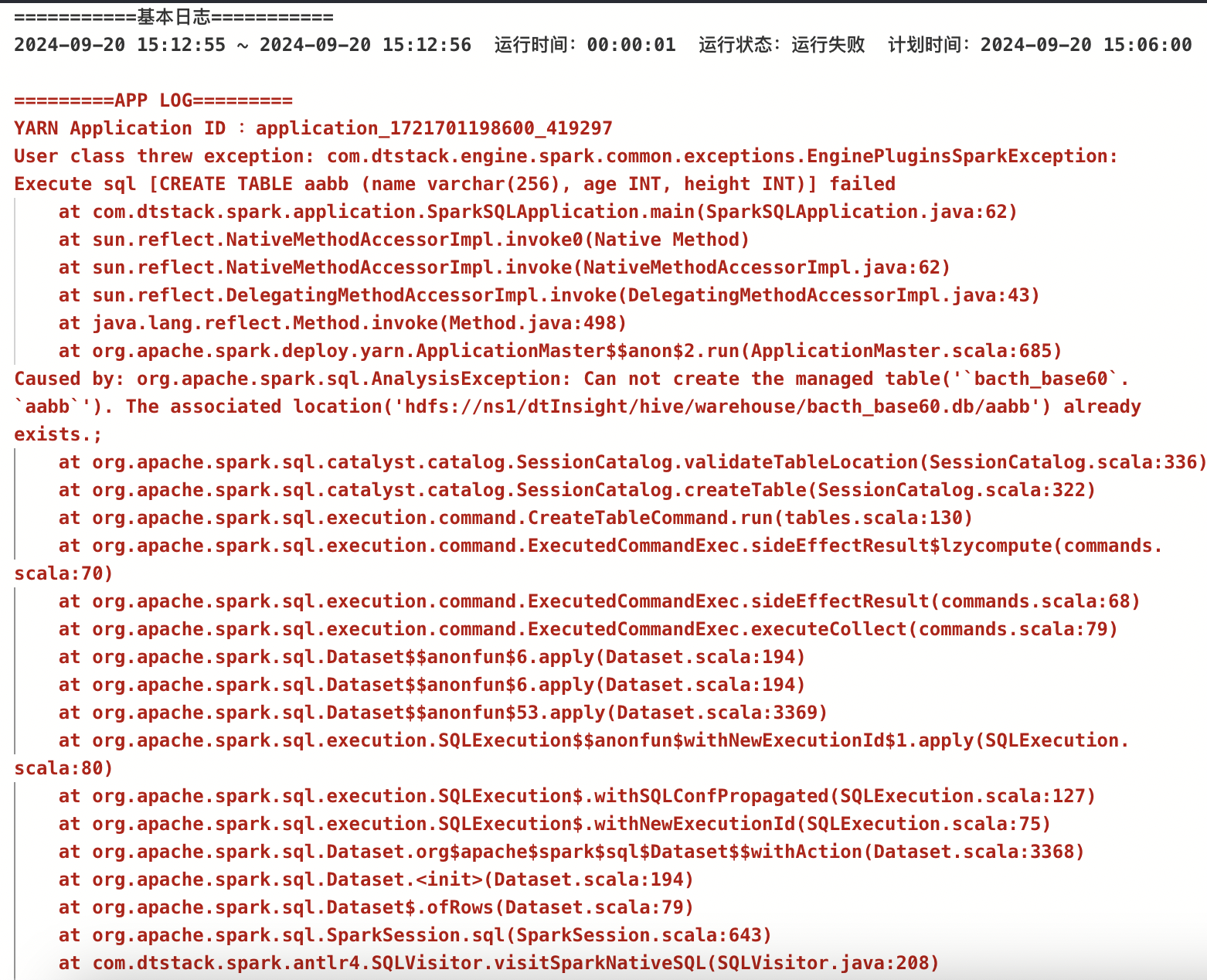
除了实时日志外,还有一些需要查看历史日志的场景。如下图:
Monarch 是 Monaco Editor 自带的一个语法高亮库,通过它,我们可以用类似 Json 的语法来实现自定义语言的语法高亮功能。这里不做过多的介绍,只介绍在本文中使用到的那部分内容.
一个语言定义基本上就是描述语言的各种属性的
JSON
值,部分通用属性如下:
tokenization
的规则。 Monaco Editor 中用于定义语言语法高亮和解析的一个核心组件。它的主要功能是将输入的代码文本分解成一个个的 token,以便于编辑器能够根据这些 token 进行语法高亮、错误检查和其他编辑功能。
false
)语言是否大小写不敏感?
tokenizer
(分词器)中的正则表达式使用这个属性去进行大小写(不)敏感匹配,以及
case
场景中的测试。
tokenizer
使用这个来轻松的定义大括号匹配,更多信息详见
@brackets
和
bracket
部分。每个方括号定义都是一个由3个元素或对象组成的数组,描述了
open左大括号
、
close右大括号
和
token令牌
类。默认定义如下:
[ ['{','}','delimiter.curly'],
['[',']','delimiter.square'],
['(',')','delimiter.parenthesis'],
['<','>','delimiter.angle'] ]
tokenizer 属性描述了如何进行词法分析,以及如何将输入转换成 token ,每个 token 都会被赋予一个 css 类名,用于在编辑器中渲染,内置的 css token 包括:
identifier entity constructor
operators tag namespace
keyword info-token type
string warn-token predefined
string.escape error-token invalid
comment debug-token
comment.doc regexp
constant attribute
delimiter .[curly,square,parenthesis,angle,array,bracket]
number .[hex,octal,binary,float]
variable .[name,value]
meta .[content]
当然也可以自定义 css token,通过以下方式将自定义的 css token 注入。
editor.defineTheme("vs", {
base: "vs",
inherit: true,
rules: [
{
token: "token-name",
foreground: "#117700",
}
],
colors: {},
});
一个 tokenizer 由一个描述状态的对象组成。tokenizer 的初始状态由 tokenizer 定义的第一个状态决定。这句话什么意思呢?查看下方例子,
root
就是 tokenizer 定义的第一个状态,就是初始状态。同理,如果把
afterIf
和
root
两个状态调换位置,那么
afterIf
就是初始状态。
monaco.languages.setMonarchTokensProvider('myLanguage', {
tokenizer: {
root: [
// 初始状态的规则
[/\d+/, 'number'], // 识别数字
[/\w+/, 'keyword'], // 识别关键字
// 转移到下一个状态
[/^if$/, { token: 'keyword', next: 'afterIf' }],
],
afterIf: [
// 处理 if 语句后的内容
[/\s+/, ''], // 忽略空白
[/[\w]+/, 'identifier'], // 识别标识符
// 返回初始状态
[/;$/, { token: '', next: 'root' }],
]
}
});
如何获取 tokenizer 定义的第一个状态呢?
class MonarchTokenizer {
...
public getInitialState(): languages.IState {
const rootState = MonarchStackElementFactory.create(null, this._lexer.start!);
return MonarchLineStateFactory.create(rootState, null);
}
...
}
通过 getInitialState 获取初始的一个状态,通过代码可以看到 确认哪个是初始状态是通过 this._lexer.start 这个属性。这个属性又是怎么被赋值的呢?
function compile() {
...
for (const key in json.tokenizer) {
if (json.tokenizer.hasOwnProperty(key)) {
if (!lexer.start) {
lexer.start = key;
}
const rules = json.tokenizer[key];
lexer.tokenizer[key] = new Array();
addRules('tokenizer.' + key, lexer.tokenizer[key], rules);
}
}
...
}
在 compile 解析 setMonarchTokensProvider 传入的语言定义对象时,会将读取出来的第一个 key 作为初始状态。可能会有疑问,就一定能保证在定义对象时,写入的第一个属性,在读取时一定第一个被读出吗?
在 JavaScript 中,对象属性的顺序有一些特定的规则:
"1"
、
"2"
等),这些属性会按照数值的升序排列。
因此,当使用
for...in
循环遍历对象的属性时,属性的顺序如下:
看个例子:
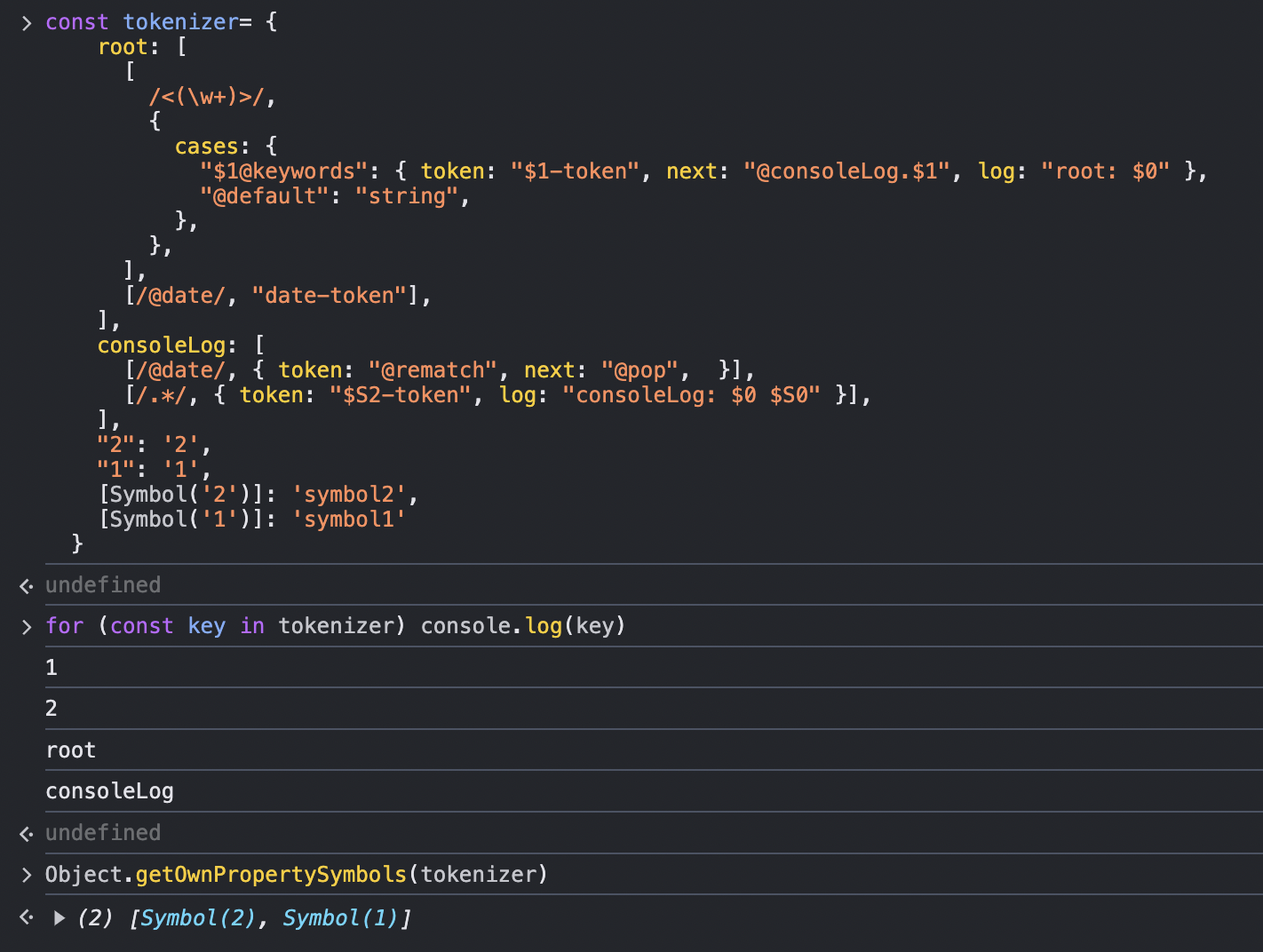
上述例子可以看出,“1”、“2”虽然被写在了后面,但仍然会被排序优先输出,其后才是字符串键根据添加顺序输出。所以,尽可能不要使用整数键去定义状态名。
当 tokenizer 处于某种状态时,只有那个状态的规则才能匹配。所有规则是按顺序进行匹配的,当匹配到第一个规则时,它的 action 将被用来确定 token 的类型。不会再使用后面的规则进行尝试,因此,以一种最有效的方式排列规则是很重要的。比如空格和标识符优先。
如何定义一个状态?
每个状态定义为一个用于匹配输入的规则数组,规则可以有如下形式:
monaco.languages.setMonarchTokensProvider('myLanguage', {
tokenizer: {
root: [
// [regex, action]
[/\d+/, 'number'],
/**
* [regex, action, next]
* [/\w+/, { token: 'keyword', next: '@pop' }] 的简写
*/
[/\w+/, 'keyword', '@pop'],
]
}
});
regex 是正则表达式,action 分为以下几种:
[/(\d)(\d)(\d)/, ['string', 'string', 'string']
monaco.languages.setMonarchTokensProvider('myLanguage', {
tokenizer: {
root: [
[/\d+/, 'number', 'word'],
],
word: [
[/\d/, '@rematch', '@pop'],
[/[^\d]+/, 'string']
]
}
});
这个 language 的状态流转图是怎么样的呢?
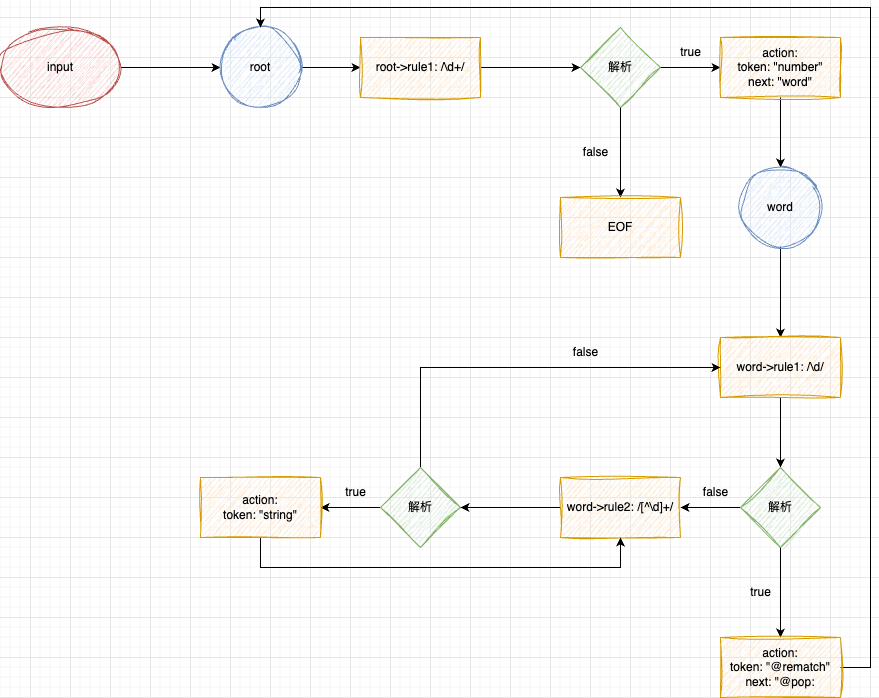
可以看出,在定义一个状态时,应保证状态存在出口即没有定义转移到其他状态的规则),否则可能会导致死循环,不断的使用状态内的规则去匹配。
monaco.languages.setMonarchTokensProvider('myLanguage', {
tokenizer: {
root: [
// 当匹配到开始标记时,推送新的状态
[/^\s*function\b/, { token: 'keyword', next: '@function' }],
],
function: [
// 在 function 状态下的匹配规则
[/^\s*{/, { token: 'delimiter.bracket', next: '@push' }],
[/[^}]+/, 'statement'],
[/^\s*}/, { token: 'delimiter.bracket', next: '@pop' }],
],
}
});
- $n
匹配输入的第n组,或者是$0代表这个匹配的输入。
- $Sn
状态的第 n 个部分,比如,状态 @tag.foo,用 $S0 代表整个状态名(即 tag.foo ),$S1 返回 tag,$S2 返回 foo 。
在本篇文章中,Monaco Editor 的使用就不再提及,不是本文的重点。利用 Monaco Editor 实现日志查看器主要是为了让不同的类型的日志有不同的高亮主题。
实时日志中,存在不同的日志类型,如:info、error、warning 等。
/**
* 日志构造器
* @param {string} log 日志内容
* @param {string} type 日志类型
*/
export function createLog(log: string, type = '') {
let now = moment().format('HH:mm:ss');
if (process.env.NODE_ENV == 'test') {
now = 'test';
}
return `[${now}] <${type}> ${log}`;
}
根据日志可以看出,每条日志都是
[xx:xx:xx]
开头,紧跟着
<日志类型>
,后面的是日志内容。(日志类型:info 、error、warning。)
注册一个自定义语言
realTimeLog
作为实时日志的一个
language
。
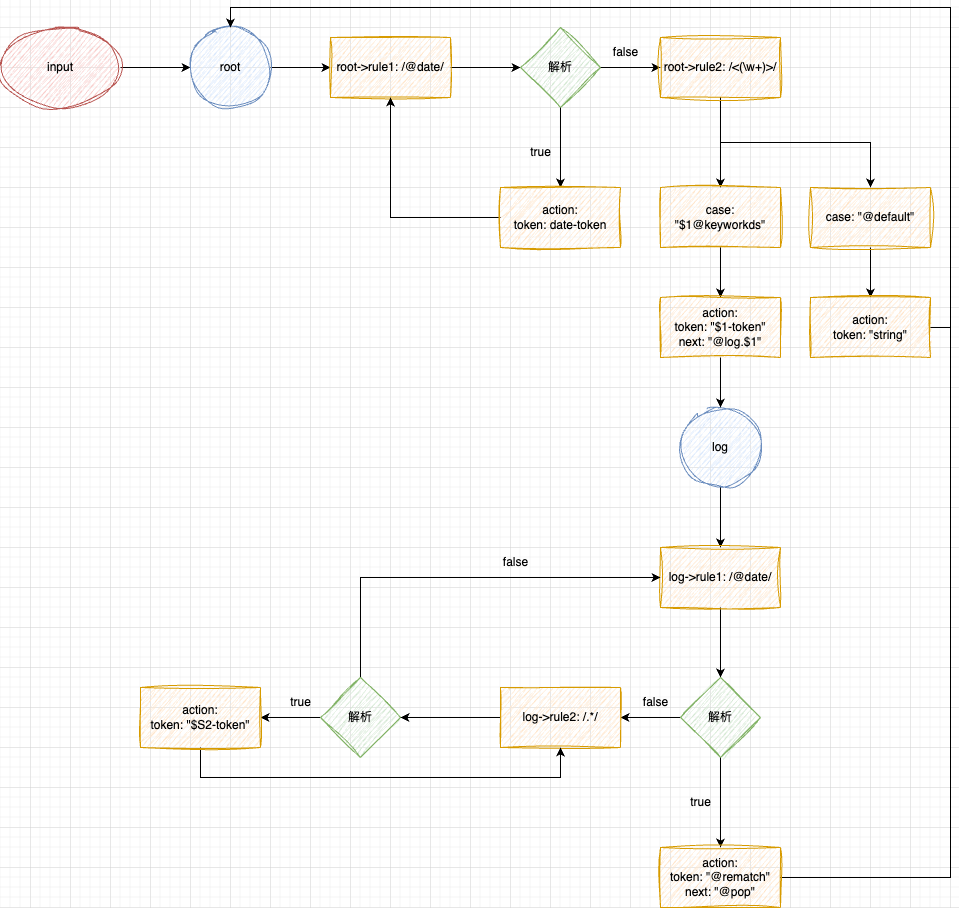
这里规则也很简单,在 root 中设置了两条解析规则,分别是匹配日志日期和日志类型。在匹配到对应的日志类型后,给匹配到的内容打上
token
,然后通过
next
携带匹配的引用标识( $1 表示正则分组中的第1组)进入下一个状态
consoleLog
,在状态
consoleLog
中,匹配日志内容,并打上
token
,直到遇见终止条件(日志日期)。
import { languages } from "monaco-editor/esm/vs/editor/editor.api";
import { LanguageIdEnum } from "./constants";
languages.register({ id: LanguageIdEnum.REALTIMELOG });
languages.setMonarchTokensProvider(LanguageIdEnum.REALTIMELOG, {
keywords: ["error", "warning", "info", "success"],
date: /\[[0-9]{2}:[0-9]{2}:[0-9]{2}\]/,
tokenizer: {
root: [
[/@date/, "date-token"],
[
/<(\w+)>/,
{
cases: {
"$1@keywords": { token: "$1-token", next: "@log.$1" },
"@default": "string",
},
},
],
],
log: [
[/@date/, { token: "@rematch", next: "@pop" }],
[/.*/, { token: "$S2-token" }],
],
},
});
// ===== 日志样式 =====
export const realTimeLogTokenThemeRules = [
{
token: "date-token",
foreground: "#117700",
},
{
token: "error-token",
foreground: "#ff0000",
fontStyle: "bold",
},
{
token: "info-token",
foreground: "#999977",
},
{
token: "warning-token",
foreground: "#aa5500",
},
{
token: "success-token",
foreground: "#669600",
},
];
状态流转图:
普通日志与实时日志有些许不同,他是的日志类型是不展示出来的,没有一个
起始/结束
标识符供
Monarch
高亮规则匹配。所以需要一个在文本中不展示,又能作为
起始/结束
的标识符。
也确实存在这么一个东西,不占宽度,又能被匹配——“零宽字符”。
零宽字符(Zero Width Characters)是指在文本中占用零宽度的字符,通常用于特定的文本处理或编码目的。它们在视觉上不可见,但在程序处理中可能会产生影响。
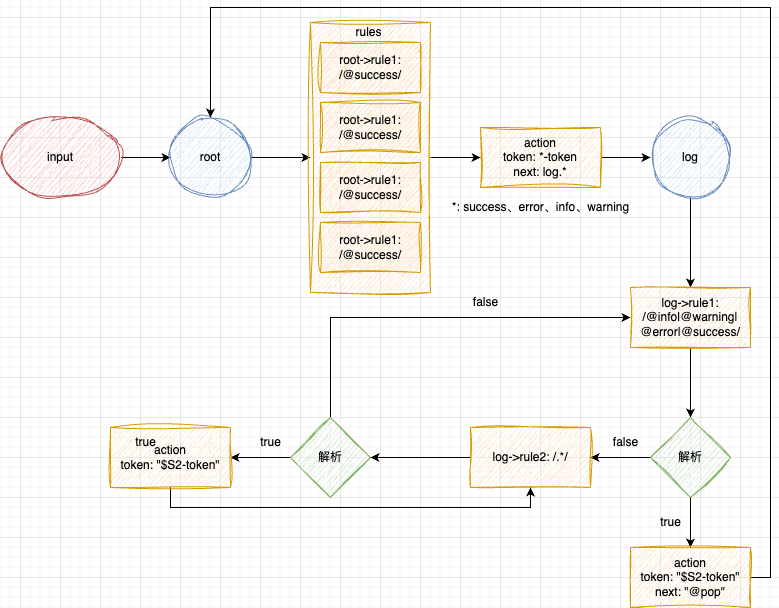
利用零宽字符创建不同日志类型的标识。
// 使用零宽字符作为不同类型的日志标识
// U+200B
const ZeroWidthSpace = '';
// U+200C
const ZeroWidthNonJoiner = '';
// U+200D
const ZeroWidthJoiner = '';
// 不同类型日志的起始 / 结束标识,用于 Monarch 语法文件的解析
const jobTag = {
info: `${ZeroWidthSpace}${ZeroWidthNonJoiner}${ZeroWidthSpace}`,
warning: `${ZeroWidthNonJoiner}${ZeroWidthSpace}${ZeroWidthNonJoiner}`,
error: `${ZeroWidthJoiner}${ZeroWidthNonJoiner}${ZeroWidthJoiner}`,
success: `${ZeroWidthSpace}${ZeroWidthNonJoiner}${ZeroWidthJoiner}`,
};
之后的编写语法高亮规则,与实时日志相同。
import { languages } from "monaco-editor/esm/vs/editor/editor.api";
import { LanguageIdEnum } from "./constants";
languages.register({ id: LanguageIdEnum.NORMALLOG });
languages.setMonarchTokensProvider(LanguageIdEnum.NORMALLOG, {
info: /\u200b\u200c\u200b/,
warning: /\u200c\u200b\u200c/,
error: /\u200d\u200c\u200d/,
success: /\u200b\u200c\u200d/,
tokenizer: {
root: [
[/@success/, { token: "success-token", next: "@log.success" }],
[/@error/, { token: "error-token", next: "@log.error" }],
[/@warning/, { token: "warning-token", next: "@log.warning" }],
[/@info/, { token: "info-token", next: "@log.info" }],
],
log: [
[
/@info|@warning|@error|@success/,
{ token: "$S2-token", next: "@pop" },
],
[/.*/, { token: "$S2-token" }],
],
},
});
// ===== 日志样式 =====
export const normalLogTokenThemeRules = [
{
token: "error-token",
foreground: "#BB0606",
fontStyle: "bold",
},
{
token: "info-token",
foreground: "#333333",
fontStyle: "bold",
},
{
token: "warning-token",
foreground: "#EE9900",
},
{
token: "success-token",
foreground: "#669600",
},
];
状态流转图:
a
元素
Monaco Editor 本身是不支持在内容中插入 HTML 元素的,原生只支持对链接进行高亮,并且支持
cmd + 点击
打开链接。但仍可能会存在需要实现类似
a
元素的效果。
另辟蹊径,查找 Monaco Editor 的 API 后,linkProvider 也许可以大致满足,但仍有不足。
以下是介绍:
在 Monaco Editor 中,linkProvider 是一个用于提供链接功能的接口。它允许开发者为编辑器中的特定文本或代码片段提供链接,当用户悬停或点击这些链接时,可以执行特定的操作,比如打开文档、跳转到定义等。
具体用法:
const linkProvider = {
provideLinks: function(model, position) {
// 返回链接数组
return [
{
range: new monaco.Range(1, 1, 1, 5), // 链接的范围
url: 'https://example.com', // 链接的 URL
tooltip: '点击访问示例' // 悬停提示
}
];
}
};
monaco.languages.registerLinkProvider('javascript', linkProvider);
它是针对已注册的语言进行注册,不会影响到其他语言。在文本内容发生变化时就会触发
provideLinks
。
根据这个 API 想到一个思路:
#link#${JSON.stringify(attrs)}#link#
包裹,attrs 是一个对象,其中包含了 a 元素的
attribute
。
a 元素标记
匹配出来,使用
attrs
的
链接文本
替换
标记文本
,并记录替换后
链接文本
在文本内容中的索引位置。利用 Monaco Editor 的
getPositionAt
获取链接文本在编辑器中的位置(起始/结束行列信息),生成
Range
。
Link
信息。在通过 linkProvider 将编辑器中对应的
链接文本
识别为链接高亮。
onMouseDown
,如果点击的内容位置在收集的 Link 中时,触发对外提供的自定义链接点击事件。
根据这一思路进行实现:
interface IAttrs {
attrs: Record;
props: {
innerHTML: string;
};
}
/**
*
* @param attrs
* @returns
*/
export function createLinkMark(attrs: IAttrs) {
return `#link#${JSON.stringify(attrs)}#link#`;
}
getLinkMark(value: string, key?: string) {
if (!value) return value;
const links: ILink[] = [];
const logRegexp = /#link#/g;
const splitPoints: any[] = [];
let indexObj = logRegexp.exec(value);
/**
* 1. 正则匹配相应的起始 / 结束标签 #link# , 两两为一组
*/
while (indexObj) {
splitPoints.push({
index: indexObj.index,
0: indexObj[0],
1: indexObj[1],
});
indexObj = logRegexp.exec(value);
}
/**
* 2. 根据步骤 1 获取的 link 标记范围,处理日志内容,并收集 link 信息
*/
/** l为起始标签,r为结束标签 */
let l = splitPoints.shift();
let r = splitPoints.shift();
/** 字符串替换中移除字符个数 */
let cutLength = 0;
let processedString = value;
/** link 信息集合 */
const collections:[number, number, string, ILink['attrs']][] = [];
while (l && r) {
const infoStr = value.slice(l.index + r[0].length, r.index);
const info = JSON.parse(infoStr);
/**
* 手动补一个空格是由于后面没有内容,导致点击链接后面的空白处,光标也是在链接上的,
* 导致当前的range也在link的range中,触发自定义点击事件
*/
const splitStr = info.props.innerHTML + ' ';
/** 将 '#link#{"attrs":{"href":"xxx"},"props":{"innerHTML":"logDownload"}}#link#' 替换为 innerHTML 中的文本 */
processedString =
processedString.slice(0, l.index - cutLength) +
splitStr +
processedString.slice(r.index + r[0].length - cutLength);
collections.push([
/** 链接的开始位置 */
l.index - cutLength,
/** 链接的结束位置 */
l.index + splitStr.length - cutLength - 1,
/** 链接地址 */
info.attrs.href,
/** 工作流中应用,点击打开子任务tab */
info.attrs,
]);
/** 记录文本替换过程中,替换文本和原文本的差值 */
cutLength += infoStr.length - splitStr.length + r[0].length * 2;
l = splitPoints.shift();
r = splitPoints.shift();
}
/**
* 3. 处理收集的 link 信息
*/
const model = editor.createModel(processedString, 'xxx');
for (const [start, end, url, attrs] of collections) {
const startPosition = model.getPositionAt(start);
const endPosition = model.getPositionAt(end);
links.push({
range: new Range(
startPosition.lineNumber,
startPosition.column,
endPosition.lineNumber,
endPosition.column
),
url,
attrs,
});
}
model.dispose();
return processedString;
}
const value = `这是一串带链接的文本:${createLinkMark({
props: {
innerHTML: '链接a'
},
attrs: {
href: 'http://www.abc.com'
}
})}`
const links = getLinkMark(value)
languages.registerLinkProvider('taskLog', {
provideLinks() {
return { links: links || [] };
},
});
onMouseDown
,在其中可以获取当前点击位置的
Range
信息,循环遍历收集的所有 Link,判断当前点击位置的
Range
是否在其中。
containsRange
方法可以判断一个
Range
是否在另一个
Range
中。
useEffect(() => {
const disposable = logEditorInstance.current?.onMouseDown((e) => {
const curRange = e.target.range;
if (curRange) {
const link = links.find((e) => {
return (e.range as Range)?.containsRange(curRange);
});
if (link) {
onLinkClick?.(link);
}
}
});
return () => {
disposable?.dispose();
};
}, [logEditorInstance.current]);
缺点:在日志实时打印时,出现链接不会立马高亮,需要等一会才会变成链接高亮。
欢迎关注【袋鼠云数栈UED团队】~
袋鼠云数栈 UED 团队持续为广大开发者分享技术成果,相继参与开源了欢迎 star
热门资讯







