
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 随着生成式人工智能(Artificial Intelligence Generated Content,简写为 AIGC)时代的到来,使用大规模预训练语言模型(LLM)来进行 text2sql 任务的 sql 生成也越来越常见。基于 LLM 的 text2SQL 方法通常分为两种:
基于 prompt 的 In context Learning(ICL)方法;
基于 text2sql 任务构建数据集并且微调开源的 LLM 以适配 text2sql 任务
基于 prompt 的方法相对来说成本较低,方法和效果都有相对成熟的结果;微调 LLM 的方法受限于消耗资源比较大,计算成本过高,没有得到很好地探索。B-GPT-Hub是一款很好的项目,这是一个基于 LLM 微调的 text2SQL 的训练推理框架和 benchmark,主要侧重于大规模微调 LLM 的方式。
主要贡献:
通过微调中型到大型 open source 的 LLM 并对 textSQL 任务进行标准化和全面的评估;
模块化且易于扩展的代码库,支持主流 LLM 和实验场景,优先考虑微调方法,并扩展到基于 prompt 的方式。
工作研究了与基于 promp 方法相比,微调方法的潜在收益和性能边界,并探索了针对特定场景的最佳解决方案。希望 DB-GPT-Hub 以及这些发现能够推动进一步的研究和广泛的应用,否则由于缺乏专门的开放基准,这些研究和应用将很难实现。
具体代码: https://github.com/eosphoros-ai/DB-GPT-Hub
文章: https://arxiv.org/abs/2406.11434
text2sql榜单: https://github.com/eosphoros-ai/Awesome-Text2SQL
Text-to-SQL(简写为 Text2SQL,或者 NL2SQL)是一项将自然语言描述转化为对应的结构化查询语句(Structured Query Language, 简写为 SQL)的技术,它能利用简洁清晰的自然语言描述,有效地辅助人们对海量的数据库进行查询,简化数据查询和分析的工作。随着生成式人工智能(Artificial Intelligence Generated Content,简写为 AIGC)时代的到来,使用大规模预训练语言模型来进行 sql 生成的方式也越来越常见。
然而在实际开发中,当前的 Text-to-SQL 技术并未与 LLM 一些优秀的特性有效结合,例如 self-instruct、思维链、分布式计算、量化微调、attention 优化等方法,此外,Text2SQL 技术如何结合强大的自然语言理解能力,实现从数据 - 模型 - 微调 - 部署 - 展示的全链路工作流程,也是亟待解决的问题。因此,在本项目中构建了一套基于微调的 text2sql 任务全链路框架,同时对现有主流的开源模型进行 text2sql 任务的评测,构建了一套 open source LLM 的 benchmark;同时也对其中的一些 insight 进行了分析。
为了充分利用大语言模型(Large Language Model,简写为 LLM)的语言理解能力,提高 Text2SQL 的模型微调效率和模型精度,在 DB-GPT 框架下提出了一个端到端大模型 Text2SQL 微调子框架 DB-GPT-Hub。在 DB-GPT 框架下,构架了 Text2SQL 领域下的数据预处理 - 模型微调 - 模型预测 - 模型验证 - 模型评估的全链路工作流程,如下图所示:
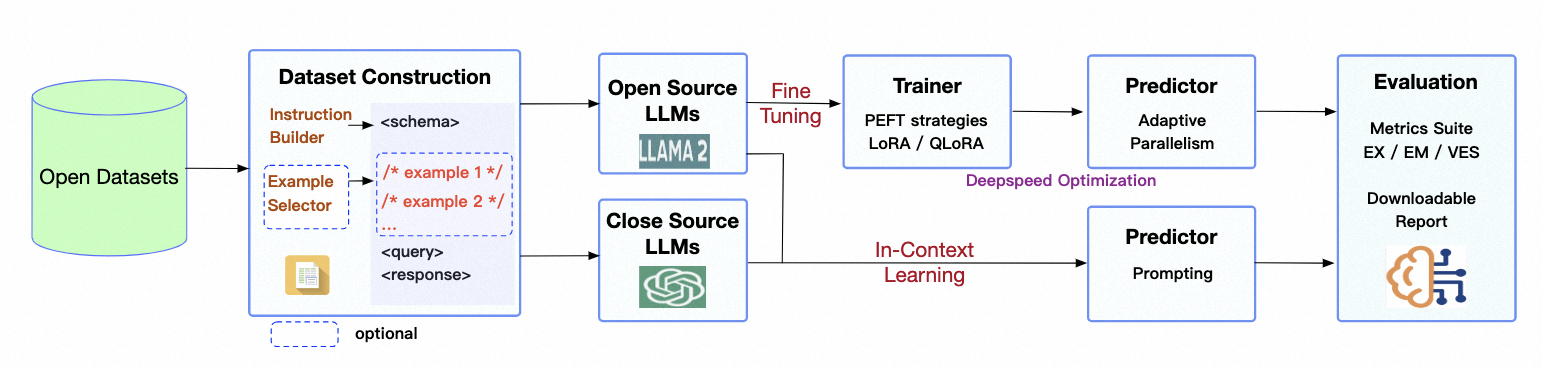
图 1.DB-GPT-Hub 的架构流程图
如图一所示:DB-GPT-Hub 项目重点关注在数据预处理 - 数据集构建 - 模型微调 - 模型预测 - 模型验证部分,微调得到的模型可以无缝衔接部署到 DB-GPT 框架中,然后结合知识问答和数据分析等能力展示模型在 Text2SQL 领域的优越性能。
具体功能:
数据集构建
:将原生的 text2SQL 数据处理成合适的格式(Text Representation Format)以微调 LLM。这包括将问题和数据库 schema 的描述集成到提示中作为指令(instruction),以及各种问题表示以提高训练和评估期间的性能。此外,将选择不同的 few-shot 策略(例如 example selection 和 organization)来构建评估数据集
训练
:的代码库支持使用 PEFT 策略对开源 LLM 进行微调。支持大多数公共架构,模型规模从小到大,例如 Qwen、Llama、Baichuan 和 ChatGLM
预测
:的代码库支持开源 LLM 的微调版本和闭源 LLM 的 SQL 查询推理。支持使用少样本和零样本方法来生成特定场景的 SQL
评估
:同时,支持不同的评测指标(EX、EM)来从不同角度评估生成的 SQL 的性能。
以开源数据集 Spider 为例做一个详细的介绍,Spider 数据集是一个多数据库、多表、单轮查询的 Text2SQL 数据集,是 Text2SQL 任务中最具挑战性的数据集之一,由耶鲁大学的 LILY 实验室于 2018 年发布,具有如下特点:
规模大:Spider 数据集包含了 10,181 个自然语言问题和 5,693 个唯一的复杂 SQL 查询,涉及到 200 个具有多个表的数据库,覆盖了 138 个不同的领域。
泛化强:Spider 数据集与之前的 Text2SQL 数据集不同的是,它在训练集和测试集中使用了不同的 SQL 查询和数据库模式,这就要求模型不仅能很好地泛化到新的 SQL 查询,而且也要泛化到新的数据库模式。
结构好: 与 WikiSQL 在每个数据库中只有一个表相比,Spider 上的每个数据库包含多个表,并且它们通过主外键联系在一起。 有
挑战:Spider 数据集包含了 SQL 中几乎所有常见的高级语法,比如 "ORDER BY", "GROUP BY", "HAVING", "JOIN”,"INSERTION" 和嵌套等,如下图所示。
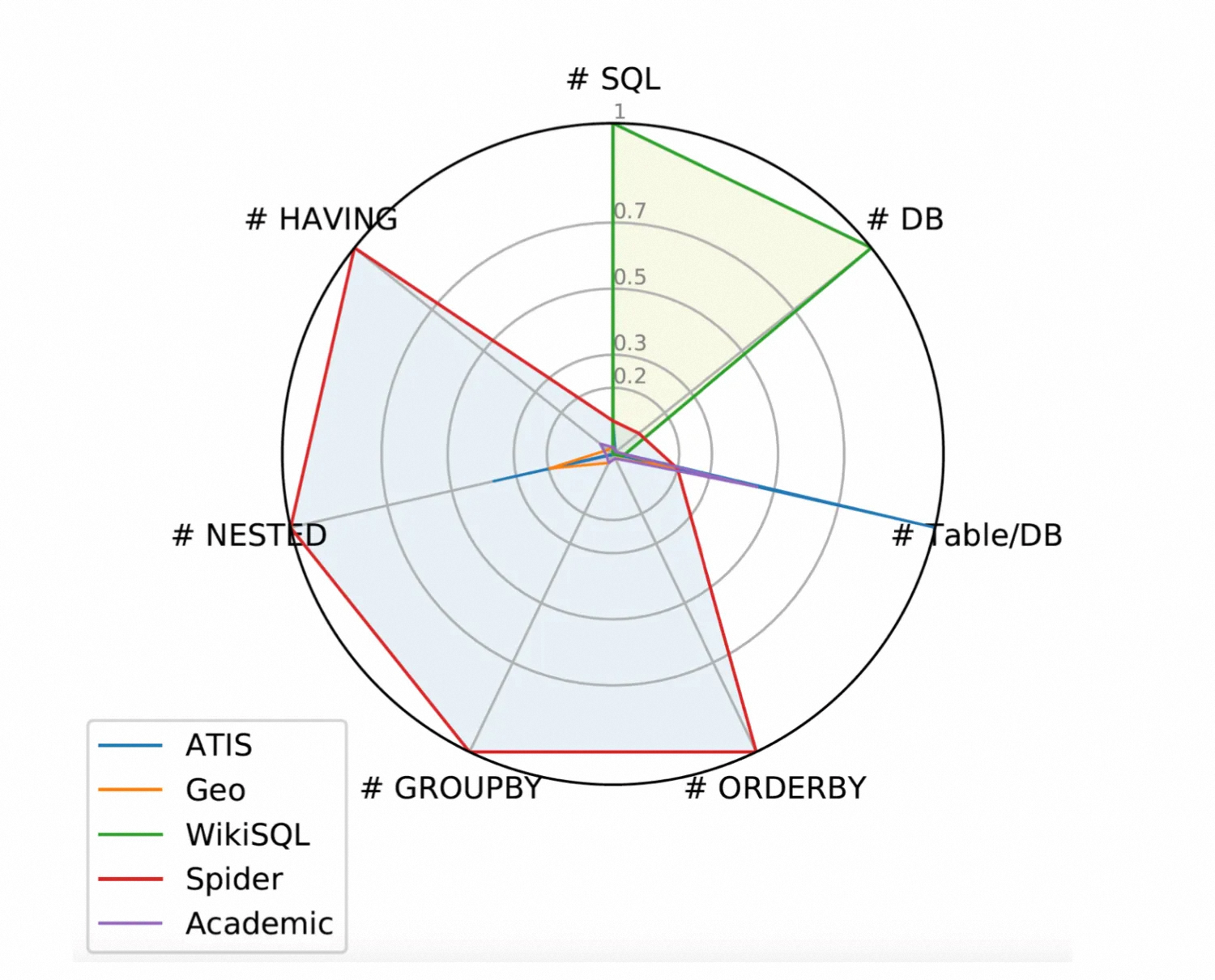
图 2: 不同数据集的语法分布
spider 数据集将 SQL 生成分成了四个等级:
简单:
Question: What is the number of cars with more than 4 cylinders?
SQL:SELECT COUNT (*)FROM cars_dataWHERE cylinders > 4
中等:
Question: For each stadium, how many concerts are there?
SQL:SELECT T2.name, COUNT (*) FROM concert AS T1 JOIN stadium AS T2ON T1.stadium_id = T2.stadium_idGROUP BY T1.stadium_id
较难
Question: Which countries in Europe have at least 3 car manufacturers?
SQL:SELECT T1.country name FROM countries AS T1 JOIN continents AS T2 ON T1.continent T2.cont_id JOIN car makers AS T3 ON T1.country_id = T3.country WHERE T2.continent = 'Europe' GROUPBY T1.country_name HAVINGCOUNT (*) >= 3
极难
Question: What is the average life expectancy in the countries where English is not the official language?
SQL:SELECT AVG(life_expectancy) FROM country WHERE name NOT IN ( SELECT T1.name FROM country AS T1 JOIN country_language AS T2 ON T1.code = T2.country_code WHERE T2.language = "English" AND T2.is_official = "T")
为了充分利用数据库中的表和字段等相关信息,对 Spider 中的原始数据进行处理,用自然语言表示数据库包含的表结构以及表结构包含的字段以及相应的主键和外键等,经过数据预处理后,可以得到如下的数据格式:
{"instruction": "concert_singer(数据库名) contains tables(表) such as stadium, singer, concert, singer_in_concert. Table stadium has columns(列) such as stadium_id, location, name, capacity, highest, lowest, average. stadium_id is the primary key(主键). Table singer has columns such as singer_id, name, country, song_name, song_release_year, age, is_male. singer_id is the primary key. Table concert has columns such as concert_id, concert_name, theme, stadium_id, year. concert_id is the primary key. Table singer_in_concert has columns such as concert_id, singer_id. concert_id is the primary key. The year of concert is the foreign key(外键)of location of stadium. The stadium_id of singer_in_concert is the foreign key of name of singer. The singer_id of singer_in_concert is the foreign key of concert_name of concert.",
"input": "How many singers do we have?",
"response": "select count(*) from singer"}
{"instruction": "concert_singer(数据库名)包含表(表),例如stadium, singer, concert, singer_in_concert。表体育场有列(列),如stadium_id、位置、名称、容量、最高、最低、平均。Stadium_id是主键(主键)。表singer有这样的列:singer_id、name、country、song_name、song_release_year、age、is_male。Singer_id为主键。表concert有如下列:concert_id、concert_name、theme、stadium_id、year。Concert_id是主键。表singer_in_concert有如下列:concert_id, singer_id。Concert_id是主键。演唱会年份是场馆位置的外键(外键)。singer_in_concert的stadium_id是歌手名的外键。singer_in_concert的singer_id是concert的concert_name的外键。
"input": "我们有多少歌手?"
"response": "select count(*) from singer"}
同时,为了更好的利用大语言模型的理解能力,定制了 prompt dict 以优化输入,如下所示:
SQL_PROMPT_DICT = {
"prompt_input": (
"I want you to act as a SQL terminal in front of an example database. "
"Below is an instruction that describes a task, Write a response that appropriately completes the request.\n\n"
"###Instruction:\n{instruction}\n\n###Input:\n{input}\n\n###Response: "
),
"prompt_no_input": (
"I want you to act as a SQL terminal in front of an example database. "
"Below is an instruction that describes a task, Write a response that appropriately completes the request.\n\n"
"###Instruction:\n{instruction}\n\n### Response: "
),
}
将从基础模型和微调方式来进行
目前支持的模型结构如下所示,包含了当下主流的中外开源模型系列,比如 Llama 系列、Baichuan 系列、GLM 系列、Qwen 系列等,覆盖面广,同时 benchmark 横跨 7b/13B/70B 的规模。

图 5: 不同模型的微调模式
Text2SQL微调主要包含以下流程:
搭建环境
数据处理
SFT训练
权重合并
模型预测
效果评估
在大语言模型对特定任务或领域进行微调任务时,重新训练所有模型参数将会带来昂贵的训练成本,因此出现了各种优化的微调方案,综合评估模型微调速度和精度,实现了当下流行的 LoRA(Low-Rank Adaptation 的简写) 方法和 QLoRA(量化 + lora)方法。 LoRA 的基本原理是在冻结原模型参数的情况下,通过向模型中加入额外的网络层,并只训练这些新增的网络层参数。由于这些新增参数数量较少,这样不仅 finetune 的成本显著下降,还能获得和全模型微调类似的效果,如下图所示:
图中蓝色部分为预训练好的模型参数,LoRA 在预训练好的模型结构旁边加入了 A 和 B 两个结构,这两个结构的参数分别初始化为高斯分布和 0
A 的输入维度和 B 的输出维度分别与原始模型的输入输出维度相同,而 A 的输出维度和 B 的输入维度是一个远小于原始模型输入输出维度的值,这就是 low-rank 的体现,可以极大地减少待训练的参数。
在训练时只更新 A、B 的参数,预训练好的模型参数是固定不变的。在推断时利用重参数思想,将 AB 与 W 合并,这样在推断时不会引入额外的计算。而且对于不同的下游任务,只需要在预训练模型基础上重新训练 AB,这样也能加快大模型的训练节奏。
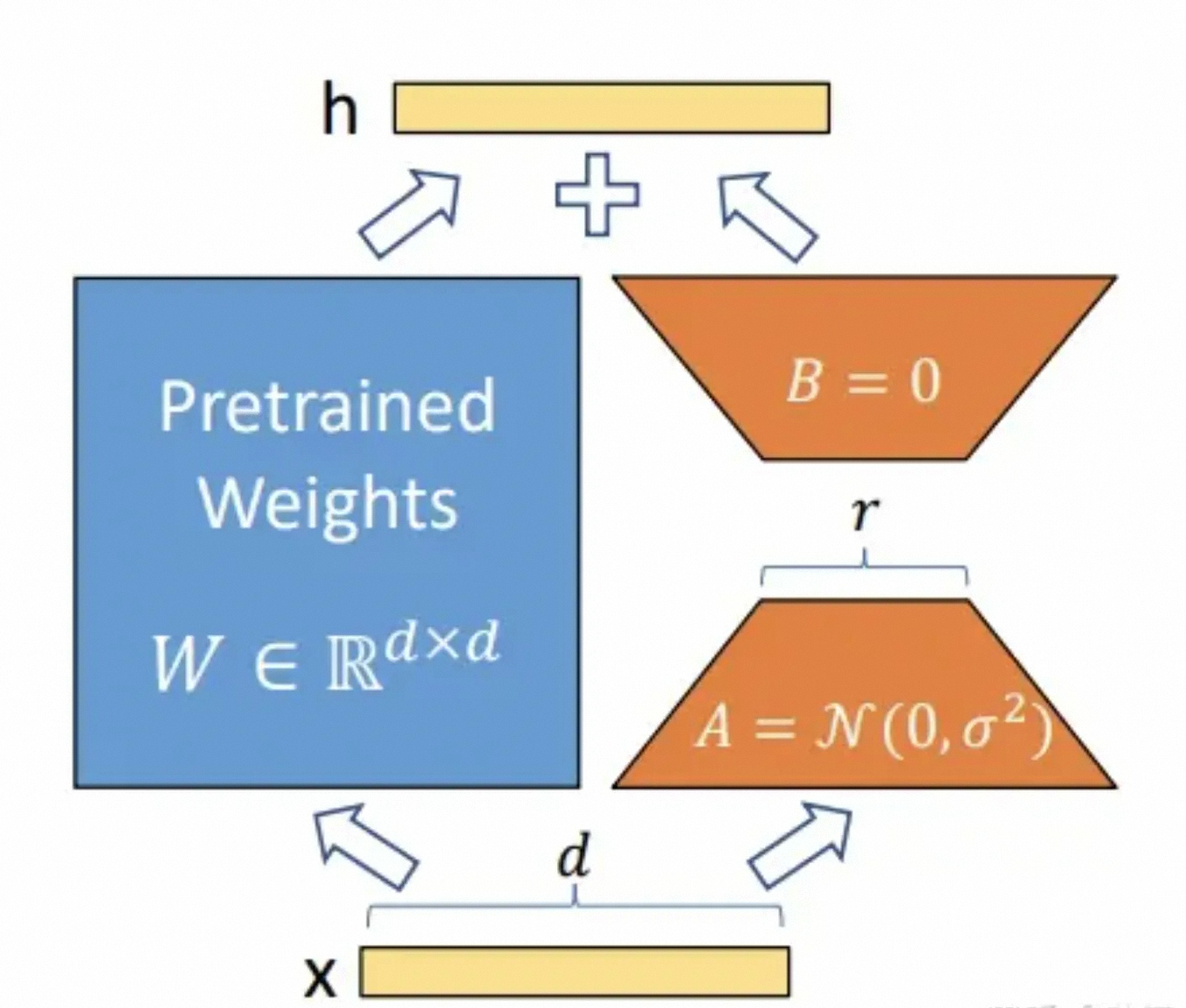
图三. LoRA 微调示意图
QLoRA 方法使用一种低精度的存储数据类型(NF4)来压缩预训练的语言模型。通过冻结 LM 参数,将相对少量的可训练参数以 Low-Rank Adapters 的形式添加到模型中,LoRA 层是在训练期间更新的唯一参数,使得模型体量大幅压缩同时推理效果几乎没有受到影响。从 QLoRA 的名字可以看出,QLoRA 实际上是 Quantize+LoRA 技术。
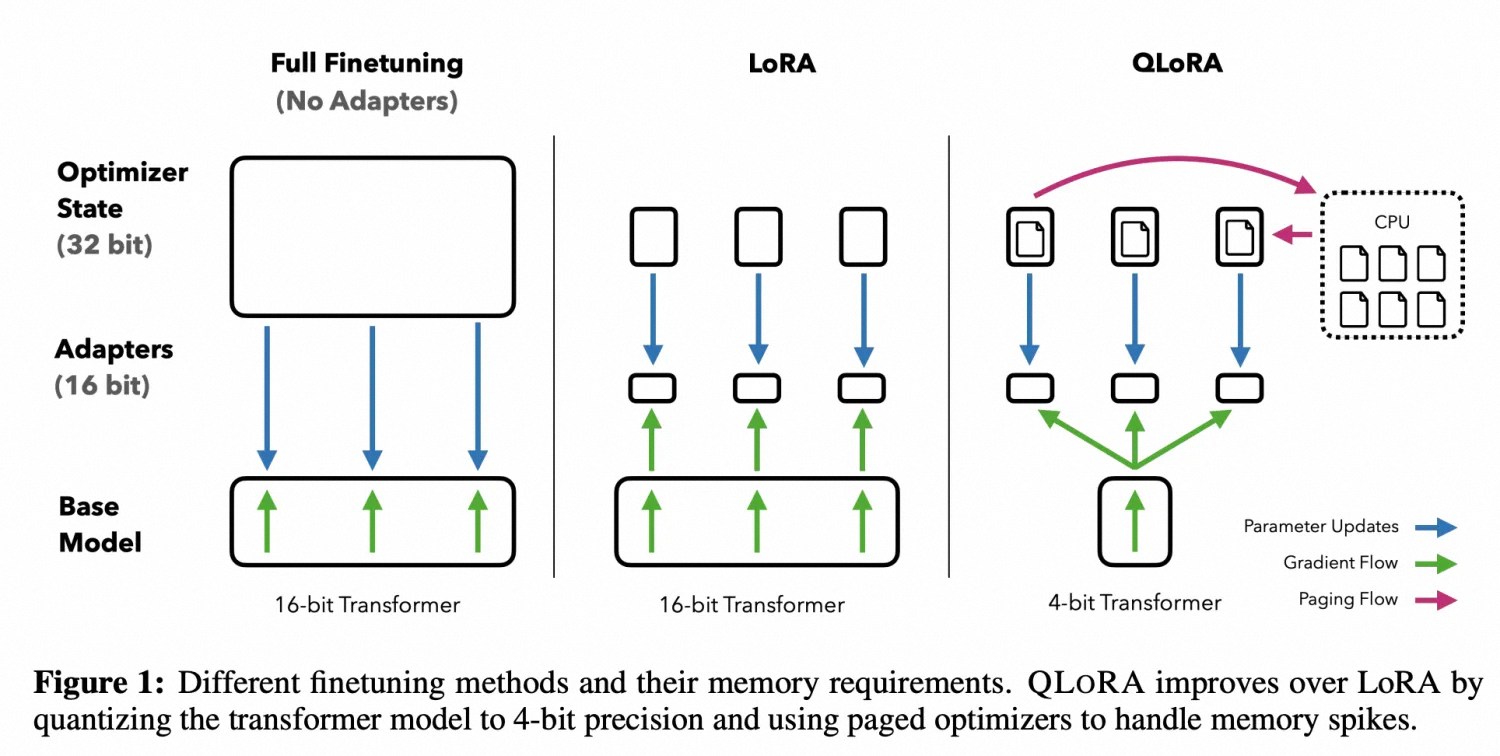
图 4:QLora 示意图
模型微调完后,基于保存的权重和基座大模型,对 spider 数据集的 dev 测试集进行测试,可以得到模型预测的 sql。 预测的 dev_sql.json 总共有 1034 条数据,同样需要经过数据预处理后,再拿给模型预测结果。
{"instruction": "concert_singer contains tables such as stadium, singer, concert, singer_in_concert. Table stadium has columns such as stadium_id, location, name, capacity, highest, lowest, average. stadium_id is the primary key. Table singer has columns such as singer_id, name, country, song_name, song_release_year, age, is_male. singer_id is the primary key. Table concert has columns such as concert_id, concert_name, theme, stadium_id, year. concert_id is the primary key. Table singer_in_concert has columns such as concert_id, singer_id. concert_id is the primary key. The stadium_id of concert is the foreign key of stadium_id of stadium. The singer_id of singer_in_concert is the foreign key of singer_id of singer. The concert_id of singer_in_concert is the foreign key of concert_id of concert.", "input": "How many singers do we have?", "output": "select count(*) from singer"}
模型预测的核心代码如下:
def inference(model: ChatModel, predict_data: List[Dict], **input_kwargs):
res = []
# test
# for item in predict_data[:20]:
for item in tqdm(predict_data, desc="Inference Progress", unit="item"):
response, _ = model.chat(query=item["input"], history=[], **input_kwargs)
res.append(response)
return res
模型预测得到 sql 后,需要和 spider 数据集的标准答案对比,使用 EX(execution accuracy)和 EM(Exact Match)指标进行评估 EX 指标是计算 SQL 执行结果正确的数量在数据集中的比例,公示如下所示:
$$
\mathrm{EX}=\frac{\Sigma_{n=1}^N \operatorname{score}\left(\hat{Y}_n, Y_n\right)}{N}
$$
EM 指标是计算模型生成的 SQL 和标注 SQL 的匹配程度。
$$
\mathrm{EM}=\frac{\sum_{n=1}^N s \operatorname{core}\left(\hat{Y}_n, Y_n\right)}{N}
$$
的 benchmark 在 bird 和 spirder 两个数据上构建:
Spider:是一个大规模跨域数据集,包含 10,181 个自然语言查询、5,693 个跨 200 个数据库的独特复杂 SQL 查询,涵盖 138 个域。此数据集的标准协议将其分为 8,659 个训练示例和 34 个数据库中的 2,147 个测试示例。SQL 查询分为四个难度级别,即简单、中等、困难和极难。
BIRD:它包含一个广泛的数据集,其中包含 12,751 个独特的问题 - SQL 对,涵盖 95 个大型数据库。SQL 查询分为三个难度级别,即简单、中等和挑战。值得注意的是,BIRD 数据集中的 SQL 查询往往比 Spider 数据集中的 SQL 查询更复杂。
整体代码适配 WikiSQL,CoSQL 等数据集。
更多内容参考: NL2SQL基础系列(1):业界顶尖排行榜、权威测评数据集及LLM大模型(Spider vs BIRD)全面对比优劣分析[Text2SQL、Text2DSL]
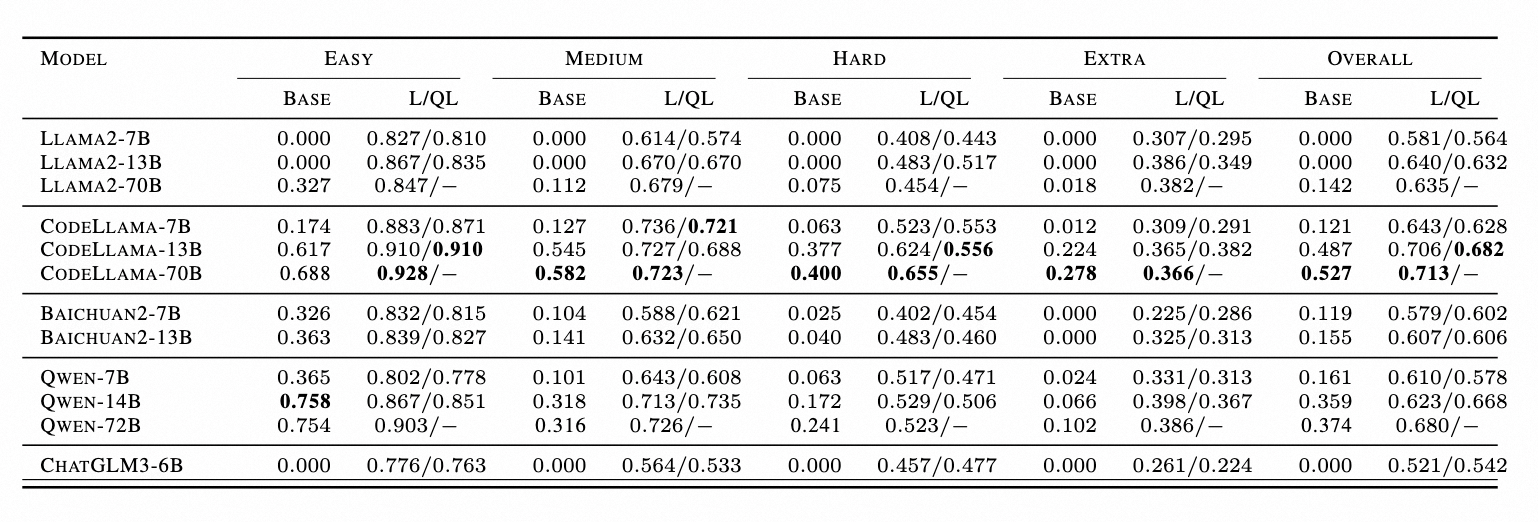
表 1.Spider 的 EX 准确率表,L 代表 LoRA,QL 代表 QLoRA
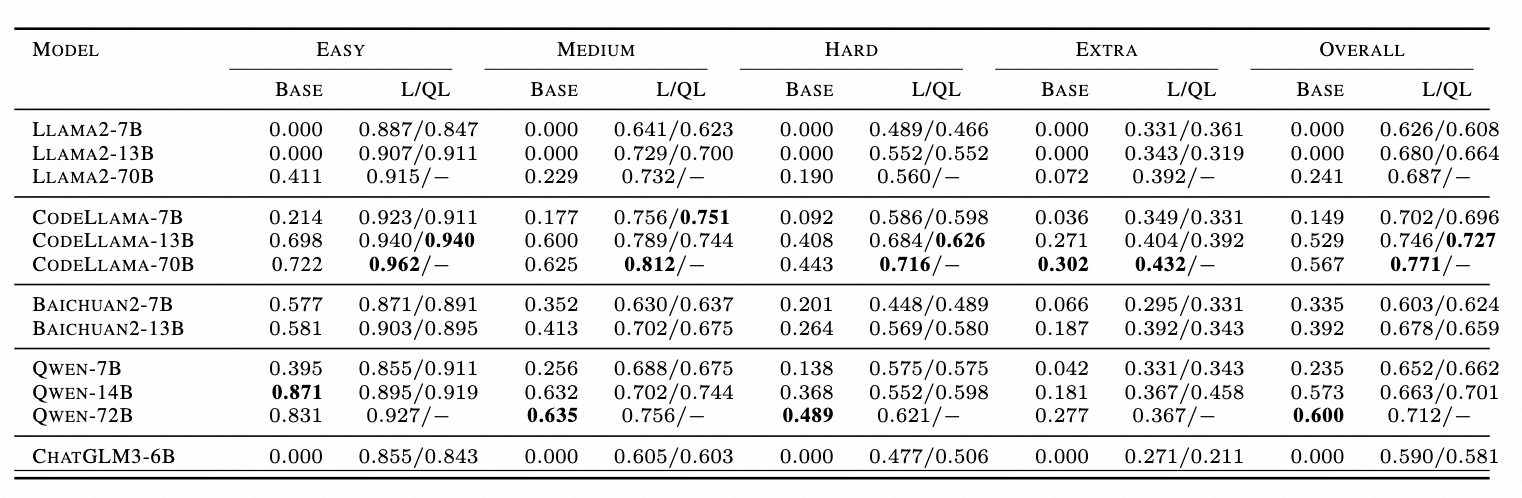
表 2.Spider 的 EM 准确率表,L 代表 LoRA,QL 代表 QLoRA
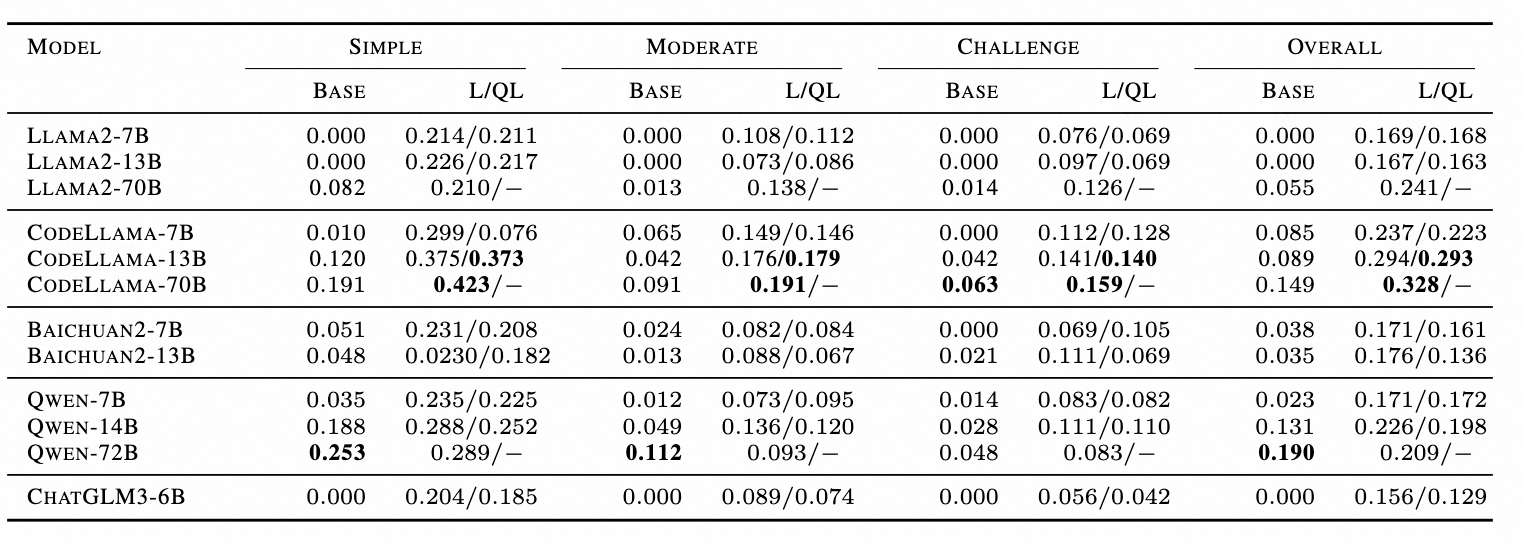
表 3.BIRD 的 EX 准确率表,L 代表 LoRA,QL 代表 QLoRA
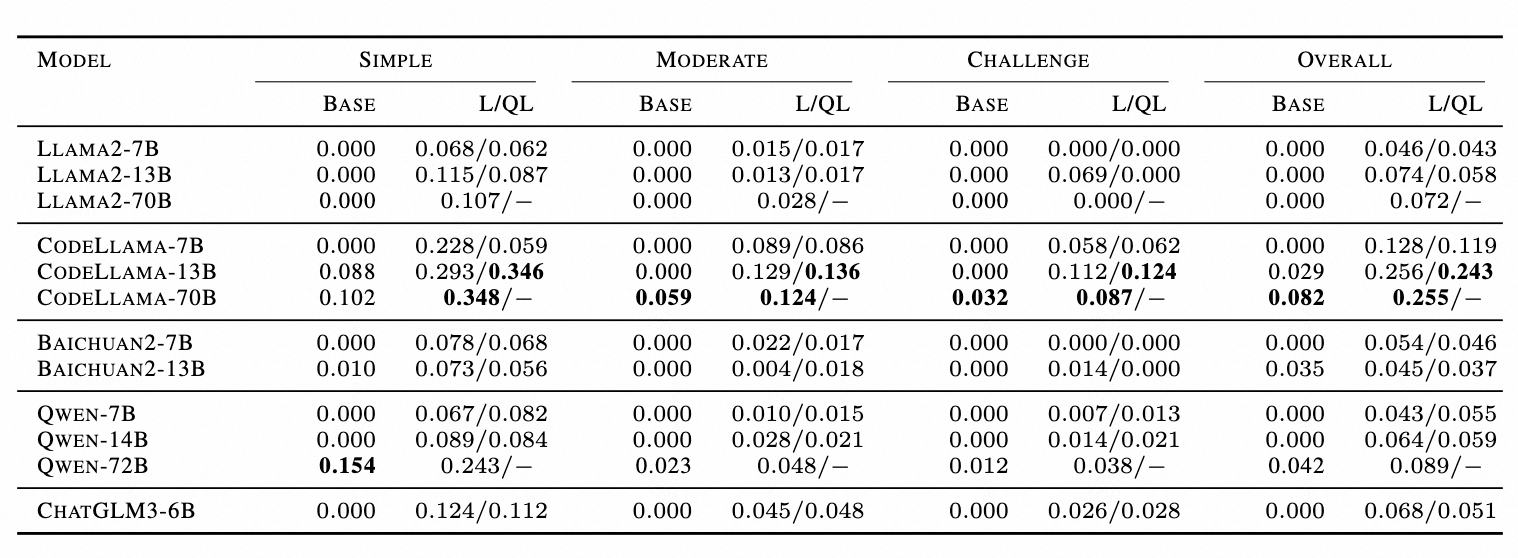
表 4.BIRD 的 EM 准确率表,L 代表 LoRA,QL 代表 QLoRA
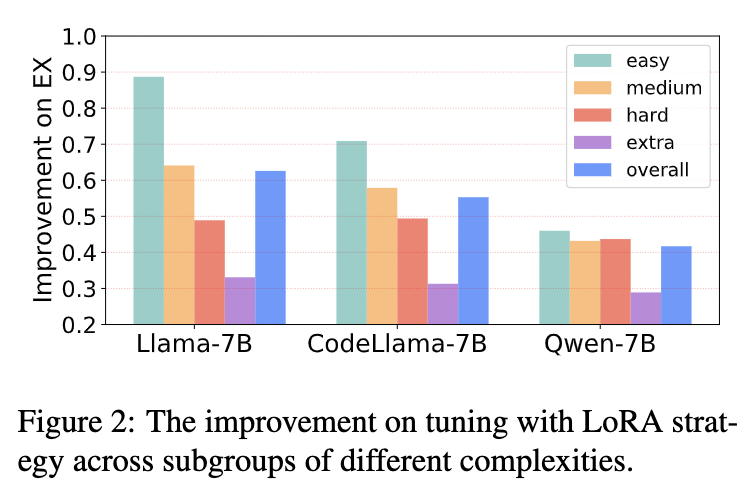
如下图所示,以三个 7B 模型为例,展示了调整后的 LLM 针对一系列 SQL 生成难度级别的有效性。对于所有三个微调后的模型,结果都表明性能提升的大小与 SQL 复杂性呈负相关,并且微调对简单 SQL 的改进更为显著。
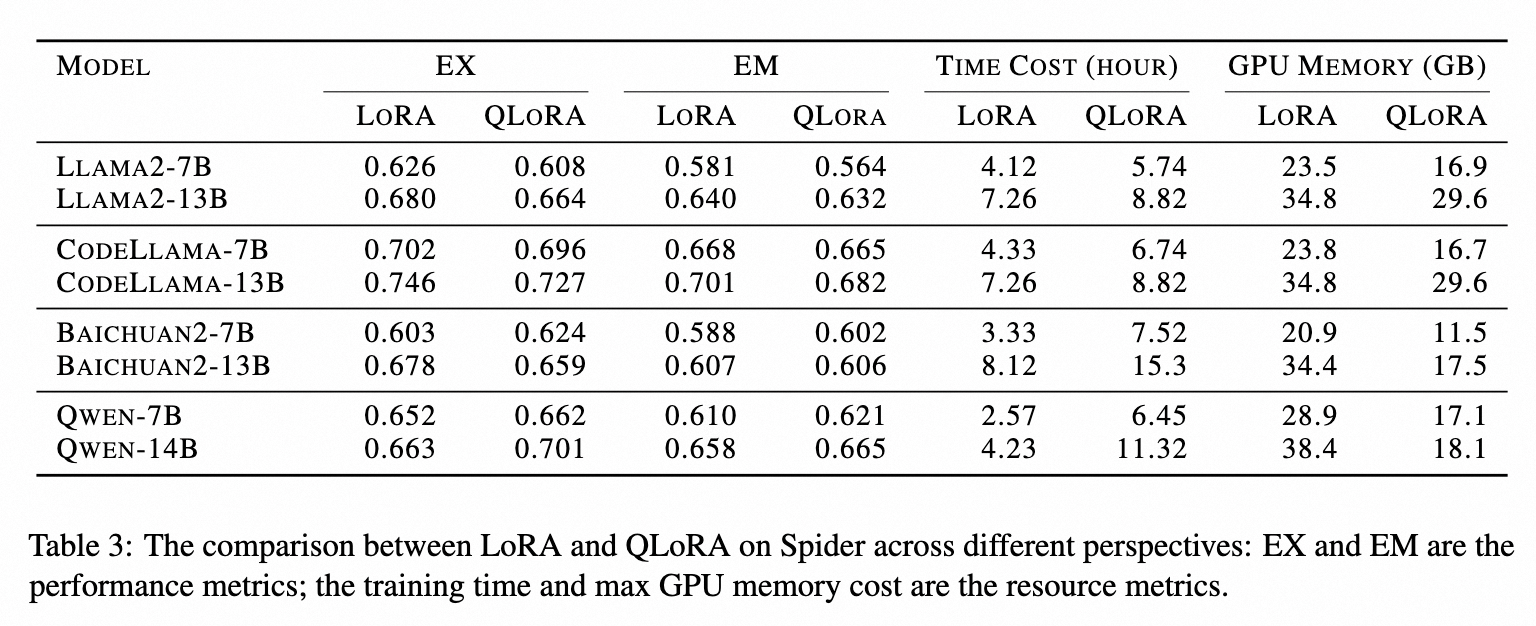
如下表所示,总结 Lora 和 QLora 在 EX、EM、时间成本和 GPU 内存指标之间的差异。首先,发现使用 LoRA 和 QLoRA 调整的模型在生成性能(以 EX 和 EM 衡量)方面差异有限。其次,与量化机制一致,QLoRA 需要更多时间才能收敛,而 GPU 内存较少。例如,与 Qwen-14B-LoRA 相比,其 QLoRA 对应模型仅需要 2 倍的时间和 50%GPU 内存
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
热门资讯







