
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 首先给大家介绍一个很好用的学习地址: https://cloudstudio.net/columns
在之前的学习中,我们已经对数据的准备工作以及数据可视化有了一定的了解。今天,我们将深入探讨基本线性回归和多项式回归的概念与应用。
如果在过程中涉及到一些数学知识,大家也不必感到畏惧,我会逐步为大家进行详细的讲解,以便大家能够更好地理解这些内容。希望通过今天的学习,能够帮助大家建立起对这两种回归方法的清晰认识,并掌握它们在实际问题中的应用。
通常情况下,回归分析主要分为两种类型:线性回归和多项式回归。线性回归旨在通过一条直线来描述变量之间的关系,而多项式回归则允许我们使用多项式函数来更灵活地捕捉数据的复杂趋势。为了帮助大家直观地理解这两种回归方法,我们可以通过图片进行展示。
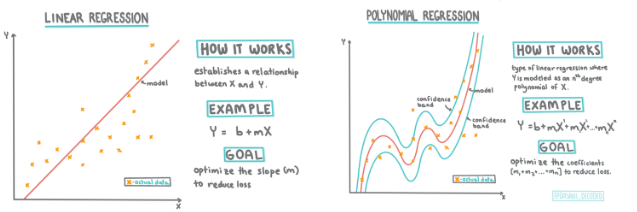
其实,线性回归和多项式回归之间的区别,可以简单地归结为直线与曲线的差异。
线性回归练习的目标在于能够绘制出一条理想的回归线,那么什么才算是“完美的线”呢?简而言之,完美的线是指使所有分散的数据点到这条线的距离最短的情况。通常,我们使用最小二乘法来实现这一目标。
理想情况下,这个总和应尽可能小,以确保回归线能够最佳地代表数据的趋势。接下来,让我们先看一下相关的数学公式,以便更深入地理解这一过程。
$ sum_{i=1}^{n} (y_i - f(x_i))^2$
我们希望求出一组未知参数,使得样本点与拟合线之间的总误差(即距离)最小化。最直观的感受如下图:
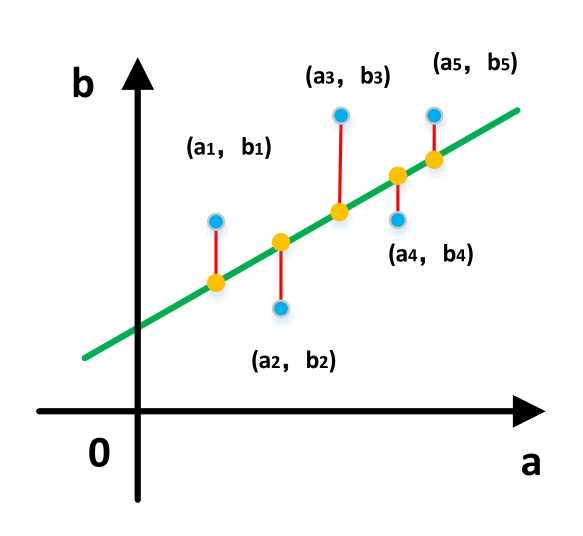
因为相减的结果可能会出现负数的情况,为了确保我们计算出的值始终为正,因此在这里引入了平方的概念。无论减法的结果是正还是负,经过平方处理后,所有的结果都将转化为正数。
这条绿线被称为最佳拟合线,可以用一个数学等式来表示:
Y = a + bX
X 是“解释变量”。Y 是“因变量”。直线的斜率是 b,a 是 y 轴截距,指的是 X = 0 时 Y 的值。
一个好的线性回归模型将是一个用最小二乘回归法与直线回归得到的高(更接近于 1)相关系数的模型。相关系数(也称为皮尔逊相关系数)我来解释一下:
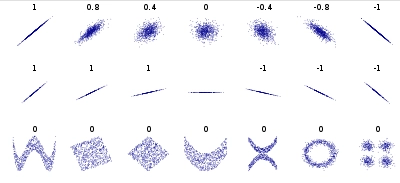
我们可以发现相关系数反映的是变量之间的线性关系和相关性的方向(第一排),而不是相关性的斜率(中间),也不是各种非线性关系(第三排)。请注意:中间的图中斜率为0,但相关系数是没有意义的,因为此时变量是0。
当然,相关性这种指标的手动计算并不实际,尤其是在面对大规模数据时,手动处理不仅效率低下,还容易出错。因此,利用现有的框架,如Scikit-learn,能够更高效、准确地进行相关性分析,让我们专注于更重要的任务。
pip install scikit-learn
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from datetime import datetime
from sklearn.preprocessing import LabelEncoder
pumpkins = pd.read_csv('../data/US-pumpkins.csv')
pumpkins.head()
在获取样本数据后,进行分析时,通常需要筛选出我们需要的字段,而那些不需要的则应予以丢弃,以便进一步深入分析。
pumpkins = pumpkins[pumpkins['Package'].str.contains('bushel', case=True, regex=True)]
columns_to_select = ['Package', 'Variety', 'City Name', 'Low Price', 'High Price', 'Date']
pumpkins = pumpkins.loc[:, columns_to_select]
price = (pumpkins['Low Price'] + pumpkins['High Price']) / 2
month = pd.DatetimeIndex(pumpkins['Date']).month
day_of_year = pd.to_datetime(pumpkins['Date']).apply(lambda dt: (dt-datetime(dt.year,1,1)).days)
new_pumpkins = pd.DataFrame(
{'Month': month,
'DayOfYear' : day_of_year,
'Variety': pumpkins['Variety'],
'City': pumpkins['City Name'],
'Package': pumpkins['Package'],
'Low Price': pumpkins['Low Price'],
'High Price': pumpkins['High Price'],
'Price': price})
new_pumpkins.loc[new_pumpkins['Package'].str.contains('1 1/9'), 'Price'] = price/1.1
new_pumpkins.loc[new_pumpkins['Package'].str.contains('1/2'), 'Price'] = price*2
new_pumpkins.iloc[:, 0:-1] = new_pumpkins.iloc[:, 0:-1].apply(LabelEncoder().fit_transform)
new_pumpkins.head()
尽管代码可能会让人感到困惑,其核心逻辑其实很简单:我们只需提取出所需的字段,包括年月、价格、城市和包装信息。如果你对编程不太熟悉,也完全没关系,现在有很多代码助手可供使用,选用任何一个都能轻松写出所需的代码。关键在于保持清晰的逻辑思路,而不是被代码的复杂性所干扰。
import matplotlib.pyplot as plt
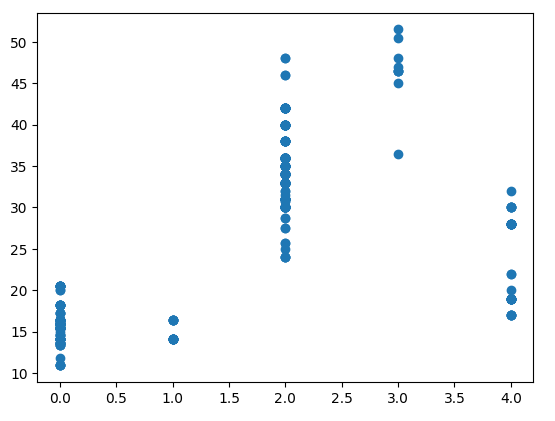
plt.scatter('City','Price',data=new_pumpkins)
正常来说,城市字段应该是文字也就是城市名字,但是因为计算的原因,这里有一段代码
new_pumpkins.iloc[:, 0:-1] = new_pumpkins.iloc[:, 0:-1].apply(LabelEncoder().fit_transform)
将数据集中的分类变量转换为数值变量,以便于后续的机器学习建模。
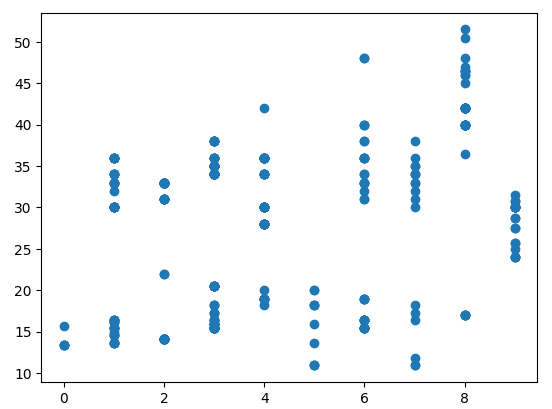
如上所示的效果图展示了我们的初步分析结果。当然,你可以选择任何一个字段来进行价格的取点分析,但通过肉眼观察,往往难以发现变量之间的相关性。不过,这并不成问题,因为现在有很多强大的工具可以帮助我们进行深入的数据分析。
print(new_pumpkins['City'].corr(new_pumpkins['Price']))
# 0.32363971816089226
确实,整个过程简单明了,一句话就可以概括。接下来,只需将剩余的分析任务交给框架即可。在这里,我们观察到相关性大约只有0.3,显示出与1的距离相当明显,这意味着变量之间的关系并不强。
因此,我们可以尝试更换另一个字段来对价格进行分析,以进一步探讨不同变量之间的相关性。
print(new_pumpkins['Package'].corr(new_pumpkins['Price']))
# 0.6061712937226021
我们清楚,影响价格的因素有很多,因此每次都单独尝试更换字段并运行代码,以判断哪个字段与价格的相关性最高,显得十分繁琐和低效。在这种情况下,我们可以采用一种更为高效的方法——构造热力图。
corr = poly_pumpkins.corr()
corr.style.background_gradient(cmap='coolwarm')
代码其实非常简单,仅需两行就能实现我们的目标。接下来,让我们一起观察运行结果,以便更好地理解这些代码的效果和输出。
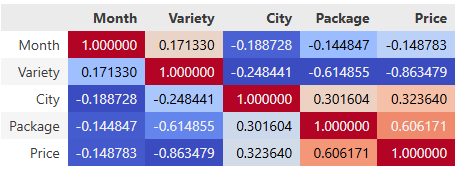
根据这些相关性系数,你可以直观地看到 Package 和 Price 之间的良好相关性。
到目前为止,我们可以初步确认,包装方式的价格与城市地区分布的价格相比,更具相关性。这一发现为我们的分析奠定了基础,因此接下来,我们将以包装方式为核心,创建一个回归模型。
new_columns = ['Package', 'Price']
lin_pumpkins = new_pumpkins.drop([c for c in new_pumpkins.columns if c not in new_columns], axis='columns')
X = lin_pumpkins.values[:, :1]
y = lin_pumpkins.values[:, 1:2]
同样的,我们只要包装和价格字段即可。让后取第一列为X轴数据,第二列为Y轴数据。
接下来,开始构建回归模型,和第一节差不多,仍然是从样本总抽取测试集以及训练集,使用Python的scikit-learn库来训练一个线性回归模型,并对测试集进行预测,代码再写一次:
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
lin_reg = LinearRegression()
lin_reg.fit(X_train,y_train)
pred = lin_reg.predict(X_test)
accuracy_score = lin_reg.score(X_train,y_train)
print('Model Accuracy: ', accuracy_score)
# Model Accuracy: 0.3315342327998987
我来简单的解释一下:
最终的分数确实不是很高,毕竟相关性也不是很好。
我们可以对已经训练好的模型进行可视化,以更直观地展示其性能和预测结果。
plt.scatter(X_test, y_test, color='black')
plt.plot(X_test, pred, color='blue', linewidth=3)
plt.xlabel('Package')
plt.ylabel('Price')
plt.show()
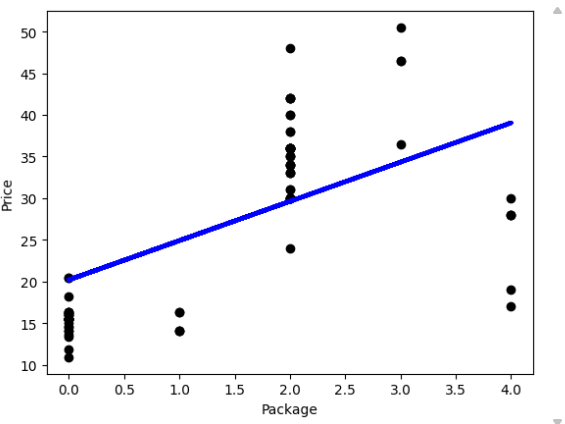
这样,我们基本上就成功实现了一个基础的线性回归模型。
另一种重要的线性回归类型是多项式回归。尽管在许多情况下,我们观察到变量之间存在直接的线性关系——例如,南瓜的体积越大,价格通常也会随之上涨——但在某些情况下,这种关系可能无法简单地用平面或直线来表示。
正如我们在上面的图例中所见,如果我们的模型采用曲线而非直线,这可能更有效地贴合数据点的分布,从而更准确地捕捉变量之间的复杂关系。
new_columns = ['Variety', 'Package', 'City', 'Month', 'Price']
poly_pumpkins = new_pumpkins.drop([c for c in new_pumpkins.columns if c not in new_columns], axis='columns')
我们重新看下数据,然后直接拿出Package和Price值。
X=poly_pumpkins.iloc[:,3:4].values
y=poly_pumpkins.iloc[:,4:5].values
接下来,我们将直接进行模型训练。在这个过程中,我们使用了另一个API,即scikit-learn库,来构建一个包含多项式特征转换和线性回归模型的管道(pipeline)。这个管道的设计旨在简化数据处理流程,使得多项式特征的生成和模型的训练能够高效地串联在一起。
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
pipeline = make_pipeline(PolynomialFeatures(4), LinearRegression())
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
pipeline.fit(np.array(X_train), y_train)
y_pred=pipeline.predict(X_test)
在这里,我想简要介绍一下PolynomialFeatures这一功能。PolynomialFeatures是scikit-learn库中用于生成多项式特征的工具。
它的主要作用是将输入的特征转换为多项式形式,从而允许我们在模型中考虑变量之间的非线性关系。例如,当我们有一个单一特征时,使用PolynomialFeatures可以创建该特征的平方、立方,甚至更高次的特征。
我们的代码中参数设置为4,意味着我们希望对输入特征X进行四次多项式转换。这种转换将使得每个原始特征生成其四次幂的组合,从而丰富我们的特征集。
为了帮助大家更直观地理解这一过程,我将提供一组示例数据,展示经过PolynomialFeatures处理后,原有的X特征数据被转化成了什么样的多项式特征。
import numpy as np
X = np.array([1, 2, 3, 4, 5])
X = X.reshape(-1, 1)
X
这是我们当前的特征集X,包含了一组简单的数据点。
array([[1],
[2],
[3],
[4],
[5]])
pp = PolynomialFeatures(4)
X_poly = pp.fit_transform(X)
print(X_poly)
转换后会生成如下:
[[ 1. 1. 1. 1. 1.]
[ 1. 2. 4. 8. 16.]
[ 1. 3. 9. 27. 81.]
[ 1. 4. 16. 64. 256.]
[ 1. 5. 25. 125. 625.]]
这样做的意义就在于:线性回归假设特征与目标之间的关系是线性的。通过多项式特征转换,可以捕捉更复杂的非线性关系。这有助于提高模型的拟合能力。
在训练过程中,模型实际上是在学习一个非线性函数,举个例子例如:二次多项式 \(y = ax^2 + bx + c\) 表示一个抛物线。
那么这个模型训练后就会产生如下效果:
df = pd.DataFrame({'x': X_test[:,0], 'y': y_pred[:,0]})
df.sort_values(by='x',inplace = True)
points = pd.DataFrame(df).to_numpy()
plt.plot(points[:, 0], points[:, 1],color="blue", linewidth=3)
plt.xlabel('Package')
plt.ylabel('Price')
plt.scatter(X,y, color="black")
plt.show()
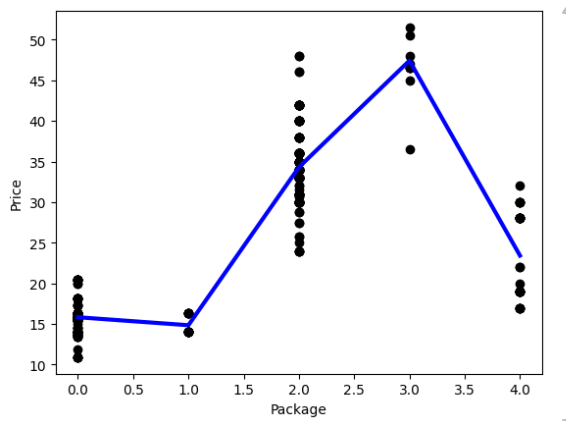
接下来,我们可以基于这个非线性模型进行预测即可。简单演示一下:
pipeline.predict( np.array([ [2.75] ]) )
# array([[46.34509342]])
在探讨线性回归和多项式回归的旅程中,我们不仅学习了如何构建模型,还理解了背后的数学原理和应用场景。通过逐步引导,希望大家对数据分析的复杂性有了更深的认识。未来,在实际问题中灵活应用这些回归技术,将使我们在数据驱动的决策中占据优势。
无论是选择合适的回归方法,还是运用强大的工具,我们都能够更有效地从数据中提炼出有价值的见解。接下来,期待大家在实践中不断探索、深入挖掘,最终实现对数据的深刻理解与应用。
我是努力的小雨,一名 Java 服务端码农,潜心研究着 AI 技术的奥秘。我热爱技术交流与分享,对开源社区充满热情。同时也是一位腾讯云创作之星、阿里云专家博主、华为云云享专家、掘金优秀作者。
? 我将不吝分享我在技术道路上的个人探索与经验,希望能为你的学习与成长带来一些启发与帮助。
? 欢迎关注努力的小雨!?
热门资讯







