
我们提供安全,免费的手游软件下载!
 小丸子漫画 最新版
小丸子漫画 最新版  起点读书 官网版
起点读书 官网版  画涯 无删减版
画涯 无删减版  飞鸟听书 去广告纯净版
飞鸟听书 去广告纯净版  西西漫画 免费漫画首页
西西漫画 免费漫画首页  蓝猫动漫 免广告最新版
蓝猫动漫 免广告最新版  扑漫漫画 免费版
扑漫漫画 免费版  新新漫画 官网入口
新新漫画 官网入口  熬夜看书 手机版
熬夜看书 手机版  小丸子漫画 无广告版
小丸子漫画 无广告版 本实验旨在通过梯度下降法实现多项式回归,探究不同阶数的多项式模型对同一组数据的拟合效果,并分析样本数量对模型拟合结果的影响。
import numpy as np
import matplotlib.pyplot as plt
# 设置随机种子以保证实验可重复性
np.random.seed(0)
# 生成20个训练样本
n_samples = 20
X = np.random.normal(0, 1, n_samples)
e_r = np.random.normal(0, 1, n_samples) # 误差项
# 计算Y值
Y = 5 + 4 * X + 3 * X**2 + 2 * X**3 + e_r
# 使用matplotlib显示生成的数据
plt.figure(figsize=(8, 6))
plt.scatter(X, Y, color='blue', label='Actual data')
plt.title('Generated Data')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()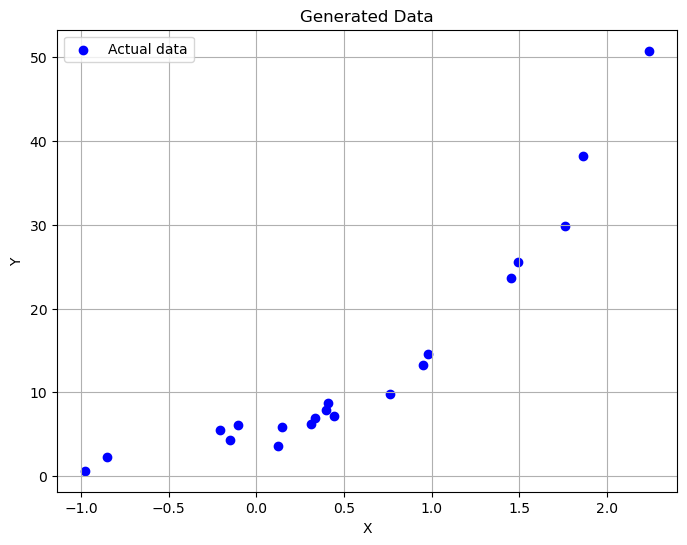
MultinomialModel
类,该类接受训练数据作为输入,并能够返回多项式模型的参数。类内部包括构造设计矩阵的方法、拟合数据的方法(使用梯度下降法)以及预测方法。
class MultinomialModel:
def __init__(self, degree):
self.degree = degree
self.coefficients = None
def _design_matrix(self, X):
"""构造设计矩阵"""
n_samples = len(X)
design_matrix = np.ones((n_samples, self.degree + 1))
for i in range(1, self.degree + 1):
design_matrix[:, i] = X ** i
return design_matrix
def fit(self, X, Y, learning_rate=0.01, iterations=1000):
"""使用梯度下降法来拟合模型"""
n_samples = len(X)
self.coefficients = np.zeros(self.degree + 1) # 初始化系数
# 构造设计矩阵
X_design = self._design_matrix(X)
for _ in range(iterations):
# 预测
predictions = np.dot(X_design, self.coefficients)
# 损失函数的导数
gradient = 2 / n_samples * np.dot(X_design.T, predictions - Y)
# 更新系数
self.coefficients -= learning_rate * gradient
def predict(self, X):
"""基于学习到的模型预测新的数据点"""
X_design = self._design_matrix(X)
return np.dot(X_design, self.coefficients)
# 使用上述定义的类
degree = 3 # 设定多项式的阶数
model = MultinomialModel(degree)
# 拟合数据
model.fit(X, Y)
# 预测
Y_pred = model.predict(X)
# 可视化拟合结果
plt.figure(figsize=(8, 6))
plt.scatter(X, Y, color='blue', label='Actual data')
plt.plot(X, Y_pred, color='red', label='Fitted curve')
plt.title('Polynomial Regression Fit')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()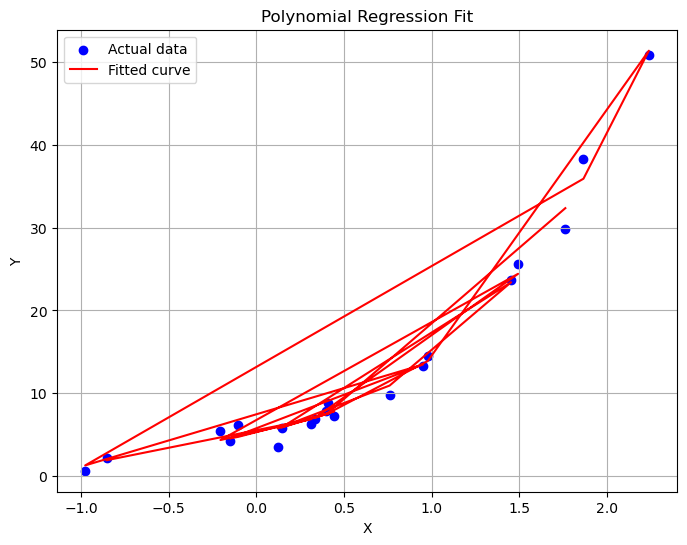
# 继续使用之前定义的MultinomialModel类
# 使用上述定义的类
degree = 3 # 设定多项式的阶数
model = MultinomialModel(degree)
# 拟合数据
model.fit(X, Y)
# 预测
Y_pred = model.predict(X)
# 创建一个从X最小值到最大值的线性空间,用于绘制平滑的拟合曲线
X_fit = np.linspace(np.min(X), np.max(X), 100)
Y_fit = model.predict(X_fit)
# 可视化拟合结果
plt.figure(figsize=(8, 6))
plt.scatter(X, Y, color='blue', label='Actual data')
plt.plot(X_fit, Y_fit, color='red', label='Fitted curve', linewidth=2)
plt.title(f'Polynomial Regression Fit (Degree {degree})')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()
# 定义不同的多项式阶数
degrees = [1, 2, 3, 4, 5]
# 创建一个新的图形
plt.figure(figsize=(10, 8))
# 对于每个多项式阶数,拟合并绘制曲线
for degree in degrees:
model = MultinomialModel(degree)
model.fit(X, Y)
# 创建一个从X最小值到最大值的线性空间,用于绘制平滑的拟合曲线
X_fit = np.linspace(np.min(X), np.max(X), 100)
Y_fit = model.predict(X_fit)
plt.plot(X_fit, Y_fit, label=f'Degree {degree}')
# 绘制实际的数据点
plt.scatter(X, Y, color='blue', label='Actual data')
# 设置图例和其他细节
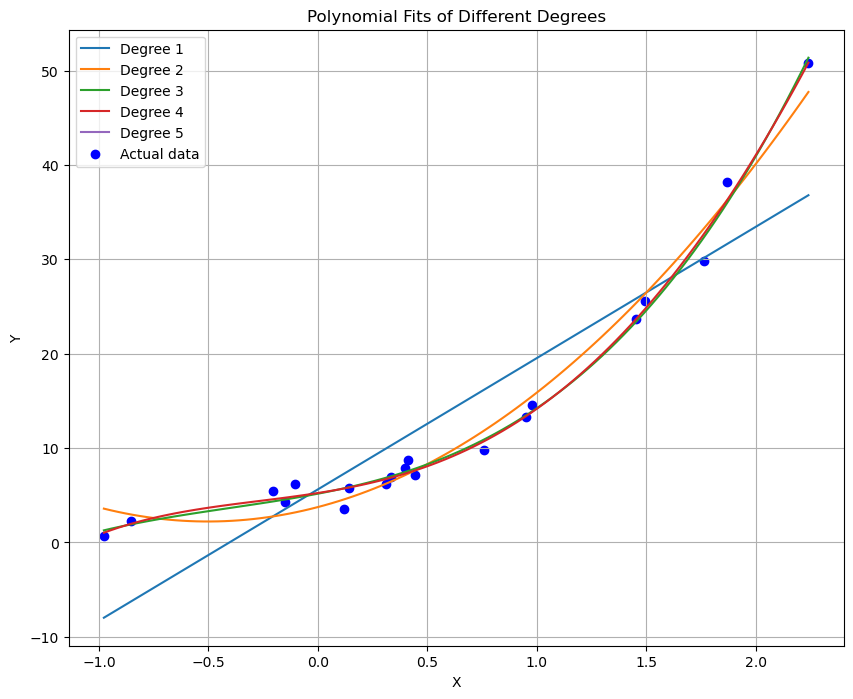
plt.title('Polynomial Fits of Different Degrees')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()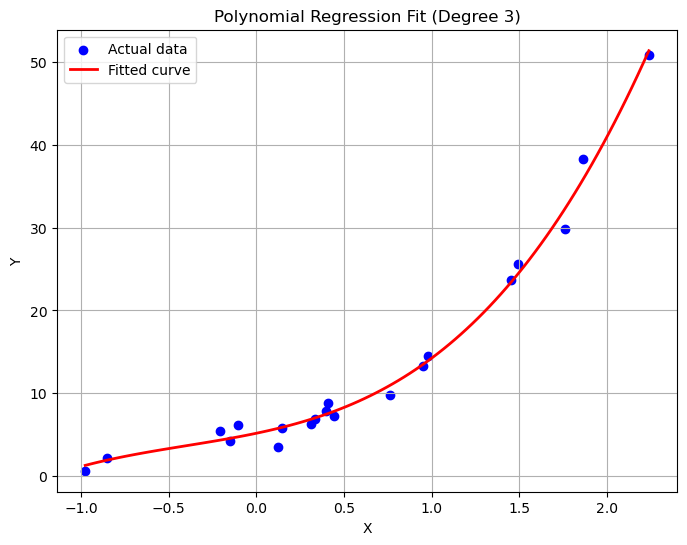
# 生成100个训练样本
n_samples = 100
X = np.random.normal(0, 1, n_samples)
e_r = np.random.normal(0, 1, n_samples) # 误差项
# 计算Y值
Y = 5 + 4 * X + 3 * X**2 + 2 * X**3 + e_r
# 使用matplotlib显示生成的数据
plt.figure(figsize=(8, 6))
plt.scatter(X, Y, color='blue', label='Actual data')
plt.title('Generated Data with 100 samples')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()
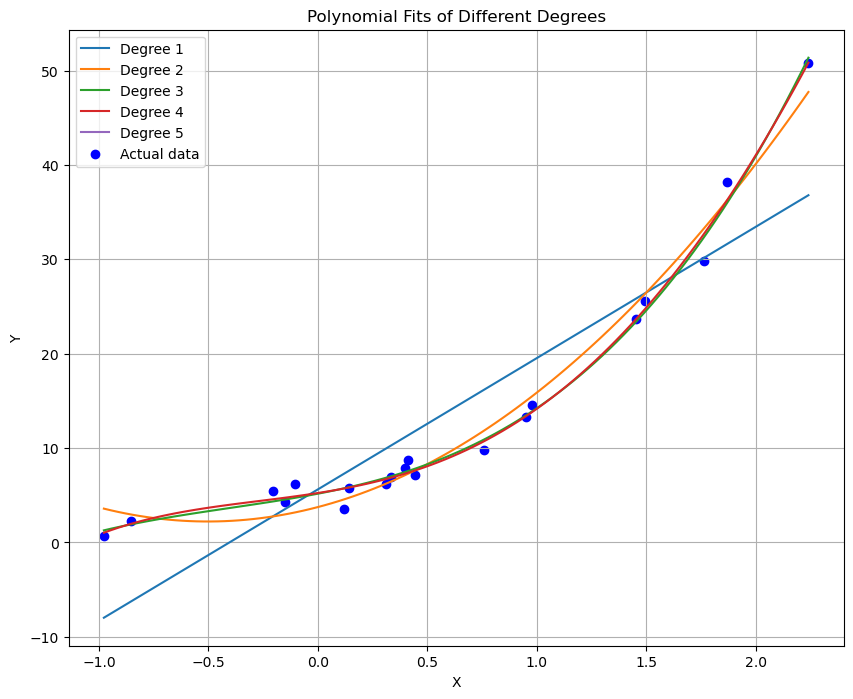
# 定义不同的多项式阶数
degrees = [1, 2, 3, 4, 5]
# 创建一个新的图形
plt.figure(figsize=(10, 8))
# 对于每个多项式阶数,拟合并绘制曲线
for degree in degrees:
model = MultinomialModel(degree)
model.fit(X, Y)
# 创建一个从X最小值到最大值的线性空间,用于绘制平滑的拟合曲线
X_fit = np.linspace(np.min(X), np.max(X), 100)
Y_fit = model.predict(X_fit)
plt.plot(X_fit, Y_fit, label=f'Degree {degree}')
# 绘制实际的数据点
plt.scatter(X, Y, color='blue', label='Actual data')
# 设置图例和其他细节
plt.title('Polynomial Fits of Different Degrees with 100 samples')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()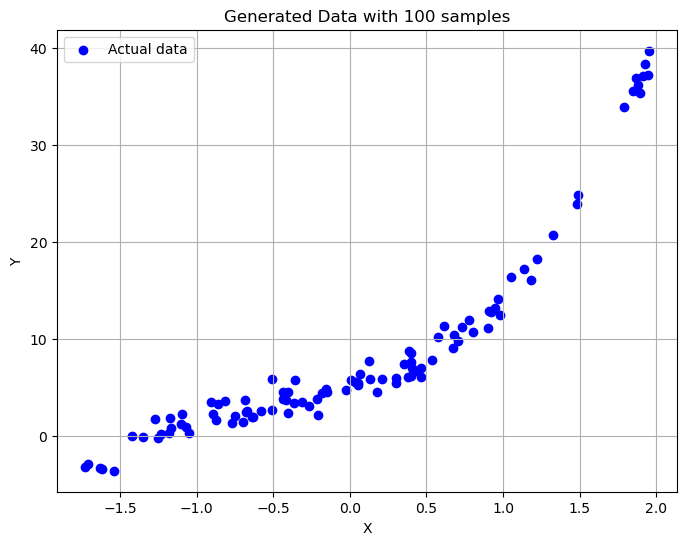
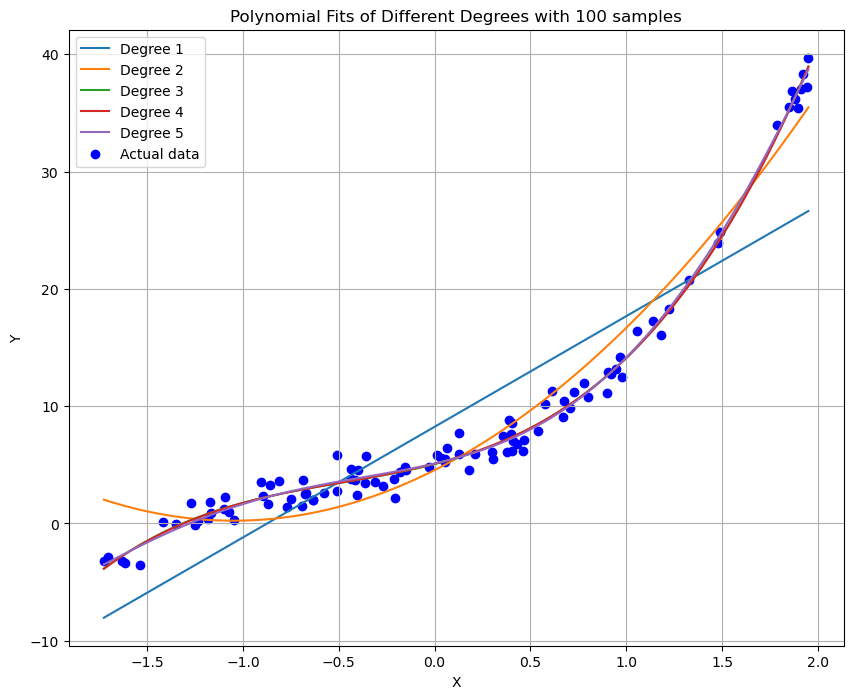
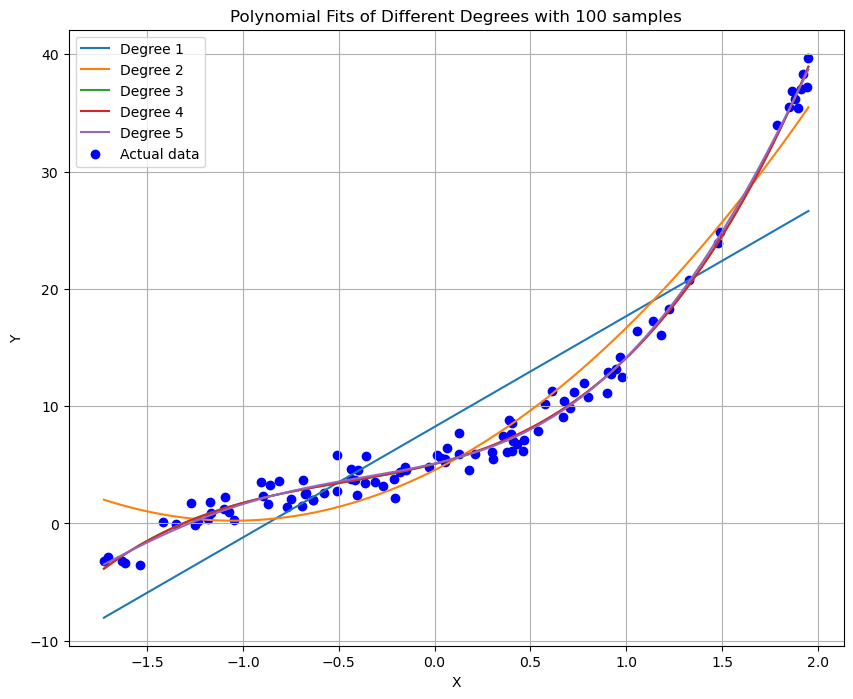
本次实验展示了如何使用梯度下降法实现多项式回归,并探讨了不同阶数及样本数量对模型拟合结果的影响。实验结果表明,在选择合适的多项式阶数以及确保有足够的训练样本的情况下,多项式回归模型可以有效地拟合非线性数据。
import numpy as np
import matplotlib.pyplot as plt
# 设置随机种子以保证实验可重复性
np.random.seed(0)
# 生成20个训练样本
n_samples = 20
X = np.random.normal(0, 1, n_samples)
e_r = np.random.normal(0, 1, n_samples) # 误差项
# 计算Y值
Y = 5 + 4 * X + 3 * X**2 + 2 * X**3 + e_r
# 使用matplotlib显示生成的数据
plt.figure(figsize=(8, 6))
plt.scatter(X, Y, color='blue', label='Actual data')
plt.title('Generated Data')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()
class MultinomialModel:
def __init__(self, degree):
self.degree = degree
self.coefficients = None
def _design_matrix(self, X):
"""构造设计矩阵"""
n_samples = len(X)
design_matrix = np.ones((n_samples, self.degree + 1))
for i in range(1, self.degree + 1):
design_matrix[:, i] = X ** i
return design_matrix
def fit(self, X, Y, learning_rate=0.01, iterations=1000):
"""使用梯度下降法来拟合模型"""
n_samples = len(X)
self.coefficients = np.zeros(self.degree + 1) # 初始化系数
# 构造设计矩阵
X_design = self._design_matrix(X)
for _ in range(iterations):
# 预测
predictions = np.dot(X_design, self.coefficients)
# 损失函数的导数
gradient = 2 / n_samples * np.dot(X_design.T, predictions - Y)
# 更新系数
self.coefficients -= learning_rate * gradient
def predict(self, X):
"""基于学习到的模型预测新的数据点"""
X_design = self._design_matrix(X)
return np.dot(X_design, self.coefficients)
# 使用上述定义的类
degree = 3 # 设定多项式的阶数
model = MultinomialModel(degree)
# 拟合数据
model.fit(X, Y)
# 预测
Y_pred = model.predict(X)
# 可视化拟合结果
plt.figure(figsize=(8, 6))
plt.scatter(X, Y, color='blue', label='Actual data')
plt.plot(X, Y_pred, color='red', label='Fitted curve')
plt.title('Polynomial Regression Fit')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()
# 继续使用之前定义的MultinomialModel类
# 使用上述定义的类
degree = 3 # 设定多项式的阶数
model = MultinomialModel(degree)
# 拟合数据
model.fit(X, Y)
# 预测
Y_pred = model.predict(X)
# 创建一个从X最小值到最大值的线性空间,用于绘制平滑的拟合曲线
X_fit = np.linspace(np.min(X), np.max(X), 100)
Y_fit = model.predict(X_fit)
# 可视化拟合结果
plt.figure(figsize=(8, 6))
plt.scatter(X, Y, color='blue', label='Actual data')
plt.plot(X_fit, Y_fit, color='red', label='Fitted curve', linewidth=2)
plt.title(f'Polynomial Regression Fit (Degree {degree})')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()
# 定义不同的多项式阶数
degrees = [1, 2, 3, 4, 5]
# 创建一个新的图形
plt.figure(figsize=(10, 8))
# 对于每个多项式阶数,拟合并绘制曲线
for degree in degrees:
model = MultinomialModel(degree)
model.fit(X, Y)
# 创建一个从X最小值到最大值的线性空间,用于绘制平滑的拟合曲线
X_fit = np.linspace(np.min(X), np.max(X), 100)
Y_fit = model.predict(X_fit)
plt.plot(X_fit, Y_fit, label=f'Degree {degree}')
# 绘制实际的数据点
plt.scatter(X, Y, color='blue', label='Actual data')
# 设置图例和其他细节
plt.title('Polynomial Fits of Different Degrees')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()
# 生成100个训练样本
n_samples = 100
X = np.random.normal(0, 1, n_samples)
e_r = np.random.normal(0, 1, n_samples) # 误差项
# 计算Y值
Y = 5 + 4 * X + 3 * X**2 + 2 * X**3 + e_r
# 使用matplotlib显示生成的数据
plt.figure(figsize=(8, 6))
plt.scatter(X, Y, color='blue', label='Actual data')
plt.title('Generated Data with 100 samples')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()
# 定义不同的多项式阶数
degrees = [1, 2, 3, 4, 5]
# 创建一个新的图形
plt.figure(figsize=(10, 8))
# 对于每个多项式阶数,拟合并绘制曲线
for degree in degrees:
model = MultinomialModel(degree)
model.fit(X, Y)
# 创建一个从X最小值到最大值的线性空间,用于绘制平滑的拟合曲线
X_fit = np.linspace(np.min(X), np.max(X), 100)
Y_fit = model.predict(X_fit)
plt.plot(X_fit, Y_fit, label=f'Degree {degree}')
# 绘制实际的数据点
plt.scatter(X, Y, color='blue', label='Actual data')
# 设置图例和其他细节
plt.title('Polynomial Fits of Different Degrees with 100 samples')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()实验中使用的代码主要包括以下几个部分:
MultinomialModel
类,并实现梯度下降法训练模型的功能。
热门资讯







